Простое руководство по Unity Job System и Burst: как правильно их использовать?
Если цель — просто многопоточность, то использование Async для переключения потоков или System.Threading — самый удобный и понятный способ. Burst также можно вызывать напрямую, не обязательно использовать Job System. Подробнее см. в статьях Асинхронность и Прямой вызов. Но если у вас множество мелких вычислений, вот тогда стоит задуматься о Job System.
Документация Unity по Job System крайне неполная. Эта статья основана на долгосрочном опыте использования и должна быть достаточно полной.
Цель и ограничения Job System
В отличие от обычного подхода к многопоточности, Unity Job System — это система, которая имитирует высокую пропускную способность GPU с помощью многопоточности на CPU. То есть, накладные расходы на распределение задач крайне малы.
Job может выполнять только объём вычислений, укладывающийся в один кадр (frame). Как и функции в CUDA/шейдерах, это маленькие ядра. Тяжёлые вычисления всё равно могут влиять на FPS, потому что Job иногда может выполняться в основном потоке. Если вам нужно выполнять длительные вычисления, либо разбивайте их на множество мелких Job, либо используйте обычные потоки .NET — они всё ещё лучший выбор.
Возникает вопрос: раз это похоже на GPU, почему бы не использовать ComputeShader напрямую? Верно, всё, что делает Job System, может делать и ComputeShader, причём удобнее. За исключением случаев:
- Если требуется часто обмениваться данными с CPU, с чем GPU справляется плохо. Job System на основе CPU имеет преимущество.
- Система ECS (DOTS) построена на Job System по той же причине.
Важно: WebGL не поддерживает Job System и ComputeShader, а также ускорение через Burst. Однако:
- WebGL заменяется на WebGPU, который поддерживает ComputeShader, и новые версии браузеров уже поддерживают его (в iOS 17 нужно включить в настройках, в 19 предпросмотре включено по умолчанию).
- В настройках WebAssembly 2023 можно включить поддержку многопоточности для Job System, и поддержка браузерами более полная. Но официально это даже не считается экспериментальной функцией, использовать нельзя. В Unity 6 LTS включение приводит к крашу. Они много лет ломают голову над многопоточностью wasm. Учитывая, что сейчас DOTS в приоритете, а .NET 8 поддерживает многопоточность wasm, возможно, они ждут Unity 7 для поддержки .NET 8.
Производительность
Приведённые показатели производительности помогут понять замысел системы и область её применения. Вы можете сначала прочитать статью, а потом вернуться к тестам.
Было протестировано 8 проектов. Сначала тестировалась производительность 3 типов аллокаторов:
- BenchAllocatorTemp: выполнить 100 000 выделений памяти через Allocator.Temp.
- BenchAllocatorTempJob: то же самое, аллокатор Allocator.TempJob.
- BenchAllocatorPersistent: то же самое, аллокатор Allocator.Persistent.
Результат: TempJob самый быстрый, затем Persistent.
Затем тестировалась производительность 4 режимов Job:
- BenchBaseLine: выполнить 100 000 простых вычислений через For в качестве базовой линии.
- BenchIJob: время планирования (scheduling) 100 000 Job.
- BenchIJobParallelFor: время пакетного планирования 100 000 Job в параллельном режиме.
- BenchIJobParallelForBurst: то же самое, но с включённым Burst.
- BenchIJobParallelForBurstLoopVectorization: запланировать 10 Job, каждая выполняет вычисления через For 10 000 раз, с включённой векторизацией Burst.
Вот результаты на моём ПК:
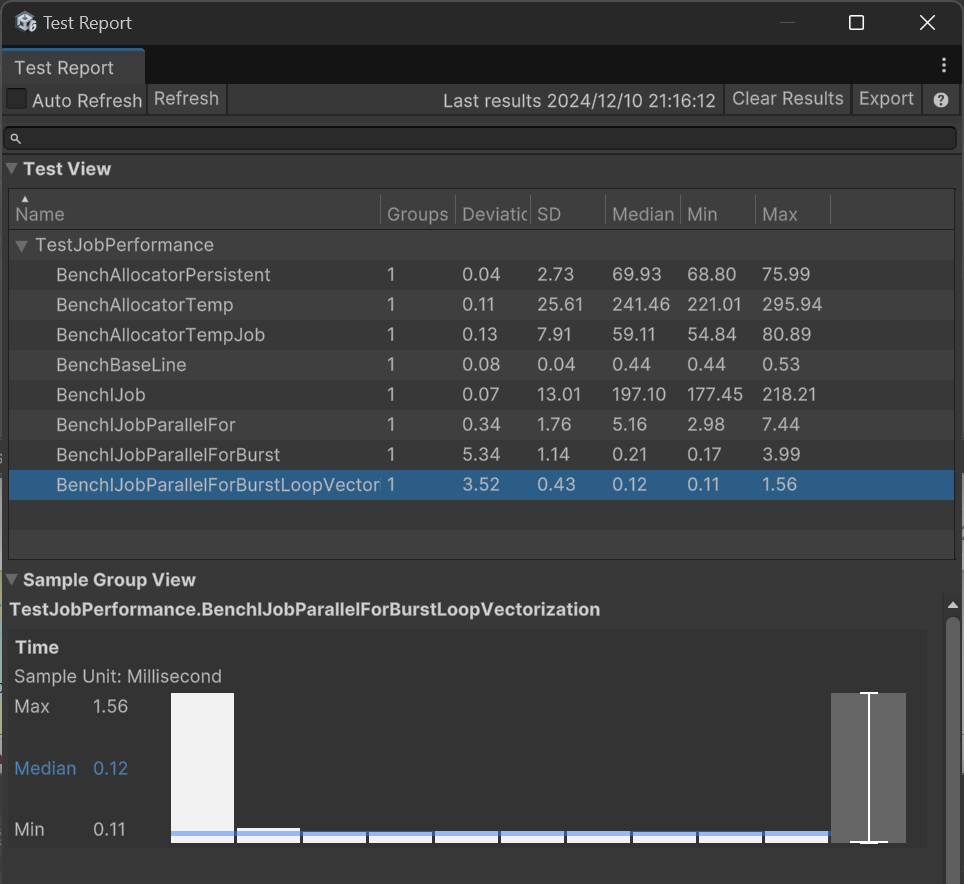
Median — это медиана времени выполнения тестового проекта, в миллисекундах.
Видно, что накладные расходы на планирование Job малы, система предназначена для выполнения огромного количества задач. Конечно, здесь я выполнял только простые операции умножения, поэтому прирост от Job System ограничен.
Типы данных
Во-первых, Burst не поддерживает управляемые (managed) типы C#. Можно использовать только типы, совместимые по размеру с C, которые можно напрямую скопировать через memcpy (без сериализации/маршалинга). Они называются blittable. К ним относятся базовые типы, такие как int и т.д. (char, string и bool иногда управляемые, не используйте их), а также одномерные C-Style массивы (new int[5]) из blittable-типов. Поскольку Job System почти всегда используется в связке с Burst, нужно следовать этим ограничениям.
Unity для этого обернула потокобезопасный тип NativeArray, специально предназначенный для Job System. Эти типы могут совместно использоваться данными с главным потоком без копирования, потому что при передаче передаётся только указатель на данные, и несколько копий ссылаются на одну и ту же область памяти. Производные типы: NativeList, NativeQueue, NativeHashMap, NativeHashSet, NativeText и др.
Важно: нельзя использовать код вида nativeArray[0].x = 1.0f или nativeArray[0]++;. Значение не изменится, потому что возвращается не ссылка.
Потокобезопасность
Потокобезопасность обеспечивается ограничениями при планировании. Один экземпляр NativeArray может быть записан только одним Job, иначе будет выброшено исключение. Если данные можно разделить для параллельной обработки, можно использовать IJobParallelFor для пакетного выполнения над NativeArray. Если данные только для чтения, можно пометить переменную-член, например: [ReadOnly] public NativeArray<int> input;.
Пока Job производит запись, главный поток не может читать NativeArray, будет ошибка. Нужно дождаться завершения.
Выделение памяти (allocate)
Во-первых, Native-типы после использования нужно вручную освобождать через Dispose(), они не уничтожаются автоматически. Для этого Unity добавила отслеживание утечек памяти.
При создании (new) Native-типов нужно выбрать один из 3 типов аллокаторов: Temp, TempJob, Persistent. Скорость выделения от самой быстрой к самой медленной. Temp имеет время жизни 1 кадр, TempJob — 4 кадра. Что это значит?
Temp— предназначен для использования внутри текущей функции,Dispose()нужно вызвать до её завершения. Если забыть Dispose, Unity выдаст ошибку при следующем рендеринге. Но на самом деле выделение через него довольно медленное.TempJob— более мягкие условия для ошибки. Фактически тоже предназначен для использования в пределах одного кадра, но Dispose можно вызвать в следующем кадре.Persistent— ошибок не будет, нужно быть внимательным самому.
Предыдущий тест производительности BenchAllocator как раз проверял производительность этих трёх. Видно, что Allocator.Temp занял в 4 раза больше времени, чем TempJob. В документации сказано, что Temp самый быстрый. Это либо баг, либо проблема режима Editor.
Выполнение однопоточного Job
Весь процесс заключается в создании своего класса, наследующего IJob, планировании его (Schedule) из главного потока, а затем вызове Complete для блокирующего ожидания завершения Job.
public struct MyJob : IJob {
public NativeArray<float> result;
public void Execute() {
for (int j = 0; j < result.Length; j++)
result[j] = result[j] * result[j];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}Но проблема в том, что мы используем Job System для большого количества задач. Одна задача мало что даёт. Более полезен параллельный режим, аналогичный GPU.
Параллельный режим (Parallel Job)
Чтобы перейти к параллельному режиму, нужно изменить наследование с IJob на IJobParallelFor в коде выше.
public struct MyJob : IJobParallelFor {
public NativeArray<float> result;
public void Execute(int i) {
result[i] = result[i] * result[i];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule(result.Length, result.Length / 10);
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}В параллельном режиме не нужно писать свой цикл For. Execute будет вызван для каждого элемента, аналогично шейдеру.
Schedule(result.Length, result.Length / 10) означает выполнение Execute для каждого элемента массива от 0 до result.Length, распределённого между 10 воркерами (worker).
О разнице в производительности между IJob и IJobParallelFor можно судить по предыдущим тестам.
Ограничения параллелизма
В IJobParallelFor вы можете записывать только в элемент с индексом i. Причём система не знает, в какой именно массив-член вы хотите записать, поэтому запись возможна только в элемент i для всех массивов. Однако можно добавить атрибут [NativeDisableParallelForRestriction] к NativeArray, чтобы отключить проверку безопасности, и самому гарантировать отсутствие конфликтов записи.
В режиме только для чтения ограничений для всех Native-контейнеров нет.
Кроме того, IJobParallelFor не может включить векторизацию цикла, если только ваши вычисления уже не используют векторизацию (вызывают другие векторизованные функции). Иначе производительность будет не оптимальной.
Использование контейнеров типа NativeList в параллельном режиме
Контейнеры, отличные от Array, такие как NativeList, в параллельном режиме могут использоваться только для чтения. Как же тогда в них писать?
По замыслу, NativeList разделяет операции Add и Set. Правильный шаблон использования: один Job выполняет операцию Add, второй — операцию Set.
Для Add можно использовать ParallelWriter и AsParallelWriter. Пример использования:
public struct AddListJob : IJobParallelFor {
public NativeList<float>.ParallelWriter result;
public void Execute(int i) {
result.AddNoResize(i);
}
}
public void RunIJobParallelForList() {
var results = new NativeList<float>(10, Allocator.TempJob);
var jobData = new AddListJob() {
result = results.AsParallelWriter(),
};
var handle = jobData.Schedule(10, 1);
handle.Complete();
Debug.Log(String.Join(",", results.ToArray(Allocator.TempJob)));
results.Dispose();
}В этом состоянии NativeList имеет фиксированную ёмкость. Перед запуском необходимо предварительно выделить память, и можно использовать только AddNoResize(). Этот метод реализован через атомарную блокировку свойства Length, что приводит к значительным потерям производительности.
Затем используется безубыточное преобразование NativeList в NativeArray: NativeList.AsDeferredJobArray(). Возвращаемый NativeArray является “ленивым” (lazy), преобразование происходит только при фактическом запуске Job, поэтому его можно передать до выполнения обоих Job:
var addJob = new AddListJob { result = results.AsParallelWriter() };
var jobHandle = addJob.Schedule(10, 1);
var setJob = new SetListJob { array = results.AsDeferredJobArray() };
setJob.Schedule(10, 1, jobHandle).Complete();Обратите внимание, что AsDeferredJobArray или AsArray возвращают View, то есть представление исходных данных. Источник данных (исходный контейнер) по-прежнему нужно освобождать через Dispose.
Параллельный режим для двумерных массивов
IJobParallelFor может параллелизовать только по отдельным элементам массива. Но на практике параллелизация по строкам двумерного массива более полезна и, кроме того, позволяет включить векторизацию цикла для большей производительности. Для этого можно использовать IJobParallelForBatch.
Сначала мы создаём плоский (flattened) двумерный массив размером [10*15]. Затем планируем его с помощью IJobParallelForBatch.Schedule(int length, int batchCount). batchCount указывает, сколько данных обрабатывает каждый job. Execute будет вызван length/batchCount раз.
var results = new NativeArray<float>(10*15, Allocator.TempJob);
var jobData = new MyJob2D {
result = results
};
var handle = jobData.Schedule(10*15, 15);
handle.Complete();
Debug.Log(String.Join(",", results));
results.Dispose();Реализация MyJob2D:
[BurstCompile]
public struct MyJob2D : IJobParallelForBatch {
public NativeArray<float> result;
public void Execute(int i, int count) {
for (int j = i; j < i + count; j++) {
result[j] = i;
}
}
}Результат выполнения:
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,
4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,
5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,
9,9,9,9,9,9,9,9,9,9,9,9,9,9,9
UnityEngine.Debug:Log (object)Этот метод позволяет Burst автоматически включить векторизацию цикла, поэтому в тестах производительности время вычисления 100 000 операций составило 0.09 мс, что является самым быстрым результатом.
Другие ограничения
- Вы не можете запускать Job изнутри другого Job.
Сочетание с Async
В примерах выше Job планируется в Update и завершается в LateUpdate с целью ускорения кода Update. Для разовых задач это не обязательно. Можно использовать Async для прямого ожидания без блокировки рендеринга. Можно использовать метод расширения CompleteAsync из пакета:
async void GenerateMesh() {
result = new NativeArray<float>(100000, Allocator.Persistent);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
await handle.CompleteAsync();
}Обратите внимание: в этом режиме нужно использовать аллокатор Persistent, потому что выполнение может не уложиться в один кадр.
Burst
Burst, основанный на LLVM, представляет собой подмножество C#, называемое “высокопроизводительным C#”, которое по сути является кодом на C. Обычно он в 10-100 раз быстрее Mono, что, конечно, говорит о медлительности Mono.
Burst может дополнительно увеличить скорость выполнения Job. Для приведённых выше примеров достаточно добавить одну строку:
[BurstCompile]
public struct MyJob : IJobParallelFor {
...
}В тестах производительности IJobParallelFor только благодаря этой строке время выполнения сократилось с 5.16 мс до 0.21 мс. Теперь скорость выполнения Job наконец превысила скорость обычного цикла For.
Примечание: все приведённые тесты производительности сделаны с 10 воркерами. Настройка количества воркеров может дать другие результаты.
Векторизация
Векторизация — это объединение нескольких вычислений в одну инструкцию. Например, вычисления с float3 по своей природе векторизованы. Для векторизации лучше всего использовать типы и методы библиотеки Unity.Mathematics, иначе она может не сработать.
Если ваши вычисления не векторизованы, можно векторизовать цикл. В предыдущих тестах производительности это позволило сократить время до 0.09 мс (см. раздел о двумерных массивах). Векторизация цикла позволяет выполнить некоторые параллельные вычисления в цикле For в одном наборе инструкций. Burst автоматически определяет возможность такой оптимизации.
Как узнать, правильно ли векторизован Job?
Откройте инструмент Burst Inspector (в меню Jobs).
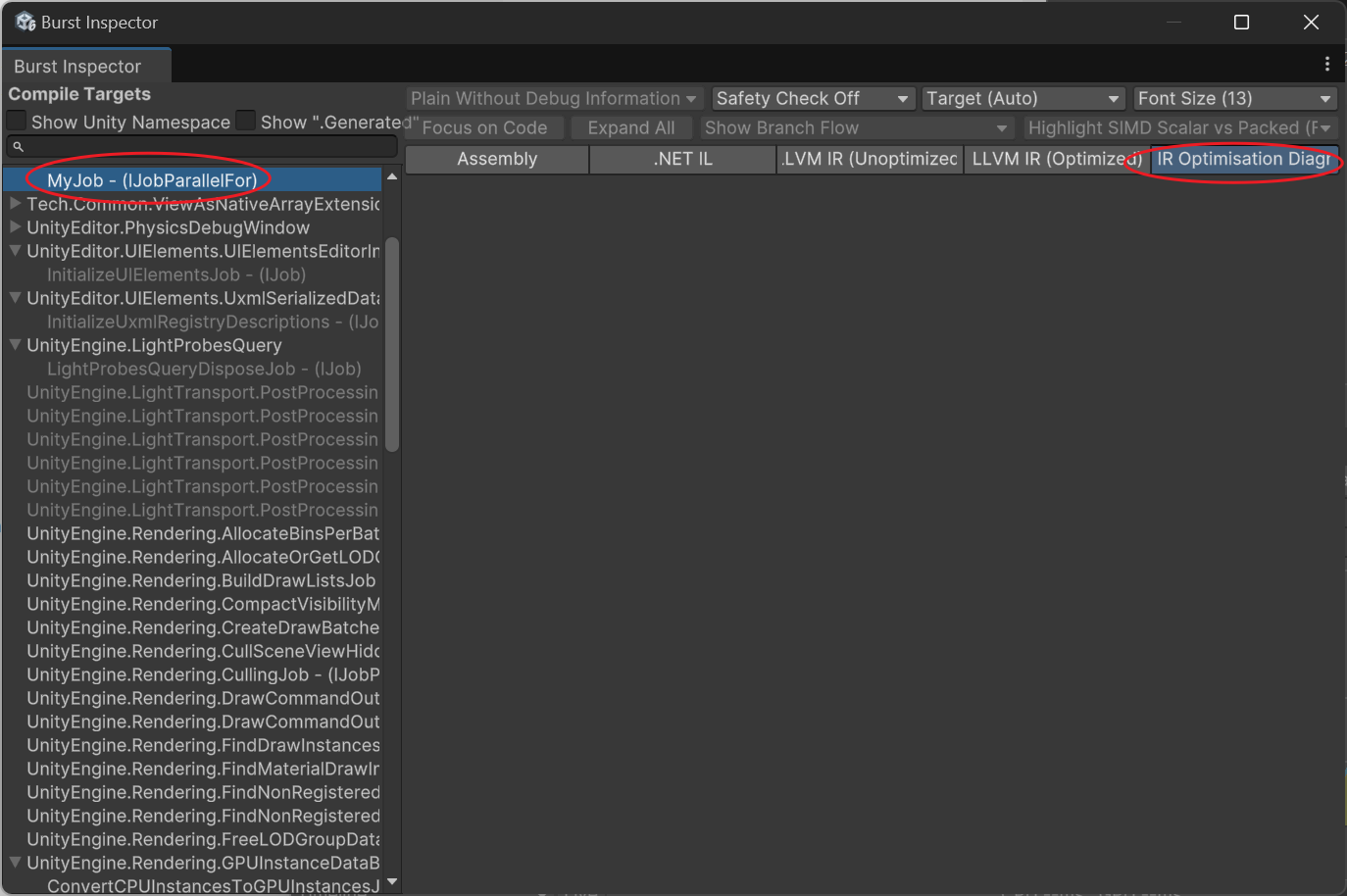
Выберите вашу функцию и посмотрите, есть ли в Assembly код с инструкциями avx, а также проверьте, нет ли предупреждений в IR Optimisation. Если векторизация не произошла, будет показано:
---------------------------
Remark Type: Analysis
Message: test.cs:30:0: loop not vectorized: call instruction cannot be vectorized
Pass: loop-vectorize
Remark: CantVectorizeInstructionReturnTypeРаспространённые сообщения:
loop not vectorized: call instruction cannot be vectorizedУказывает на вызов внешней функции, которую нельзя векторизовать.loop not vectorized: instruction return type cannot be vectorizedОбычно это означает вызов уже оптимизированной функции, поэтому повторная векторизация невозможна. Это нормально.
Преобразование данных Unity для Job System
Самая болезненная часть работы с Job System и Burst — необходимость преобразовывать различные данные в NativeArray.
Например, Vector3 нужно заменить на float3. При одинаковом размере можно выполнить прямое приведение типа. Пример:
var floats = new NativeArray<float3>(100, Allocator.TempJob);
NativeArray<Vector3> vertices = floats.Reinterpret<Vector3>();
Vector3[] verticesArray = vertices.ToArray();
floats.Dispose();Также можно преобразовать (Reinterpret) в структуру, например, превратить 3 float в 1 vector3:
var floats = new NativeArray<float>(new float[] {1,2,3}, Allocator.TempJob);
NativeArray<Vector3> aaa = floats.Reinterpret<Vector3>(sizeof(float));
Debug.Log(string.Join("\n", aaa.Select(v => v.ToString())));
floats.Dispose();(1.00, 2.00, 3.00)Для приведения типа (cast), например, из NativeArray<int> в NativeArray<ushort>, потребуется создать собственный Job для преобразования.
JobSystem с автоматическим пакетным выполнением на платформе WebGL
Код JobSystem на платформе WebGL выполняется в главном потоке, поэтому большое количество задач в IJobParallelFor может полностью заблокировать игру.
Можно создать собственный интерфейс AdaptSchedule, который автоматически определяет, находится ли игра в среде WebGL или в многопоточной среде. В WebGL он будет выполнять задачи пакетами, по количеству worker за кадр. Каждый шаг будет yield return Awaitable, давая главному потоку передышку.
Заключение
Burst — это, по сути, компромиссный способ ускорения кода. Это порождает менталитет, при котором хочется, чтобы всё было совместимо с Burst. В итоге код становится уродливым, компиляция замедляется, и в библиотеках DOTS повсюду видны следы этого. Unity и так становится всё более раздутой и медленной при компиляции из-за роста энтропии. Для более широкого применения DOTS эту проблему необходимо решить.
Unity 7 будет поддерживать .NET 8+ и CoreCLR. Это увеличит скорость компиляции в Editor, позволит использовать многие новые возможности .NET и снизит затраты на взаимодействие с кодом на C. Давайте немного понадеемся, что в будущем не придётся так часто использовать Burst.
Редакция от февраля: Ведущий руководитель, ответственный за CoreCLR, ушёл в отставку из-за разногласий во мнениях. Всем расходиться.