Unity JobシステムとBurst完全ガイド:正しい使い方は?
もし単純にマルチスレッドが目的であれば、Asyncでスレッドを切り替えるか、System.Threadingを使うのが最も便利で明確な方法です。Burstも直接呼び出せますし、必ずしもJobは必要ありません。詳細は非同期編と直接呼び出し編の記事を参照してください。しかし、大量の小さな計算がある場合、その時初めてJobシステムを検討すべきです。
UnityのJobに関するドキュメントは極めて不完全です。本記事は長期間の使用経験に基づく記録であり、比較的包括的であるはずです。
Jobの目的と制限
一般的なマルチスレッドの考え方とは異なり、Unity Jobシステムは、マルチスレッドを用いてGPUの高いスループットをシミュレートするシステムです。つまり、タスクの割り当てオーバーヘッドが極めて小さいのです。
Jobは1フレーム内の計算量しか担えず、CUDA/シェーダーの関数と同様に小さなカーネルです。重い計算は依然としてFPSに影響を与えます。なぜなら、Jobは時々メインスレッドで実行されるからです。長時間の計算を実行したい場合は、多くの小さなJobに分割するか、そうでなければ .Net スレッドが依然として最良です。
では疑問が湧きます。GPUに似ているなら、なぜ直接ComputeShaderを使わないのか?その通り、Jobの仕事はComputeShaderでも全て可能であり、さらに便利です。ただし、以下の場合は例外です:
- CPUと頻繁にデータを交換する必要がある場合、GPUはこれを得意としないため、CPUベースのJobが優位になります。
- ECS(DOTS)システムはJobを基盤としており、理由は上記と同じです。
注意:WebGLはJobとComputeShaderをサポートしておらず、Burstによる高速化もサポートしていません。しかし:
- WebGLはWebGPUに置き換えられつつあり、WebGPUはComputeShaderをサポートしており、新しいブラウザは既にサポートしています(iOS 17では設定で有効にする必要がありますが、19プレビューではデフォルトで有効になっています)。
- 設定のWebAssembly 2023でマルチスレッドを有効にするとJobをサポートでき、ブラウザのサポートもより包括的です。しかし、公式には実験的機能ですらなく、使用不可とされており、Unity6 LTSで有効にするとクラッシュします。wasmマルチスレッドについては彼らは何年も悩んでおり、現在DOTSが比較的重要視されていること、さらに .Net 8がwasmマルチスレッドをサポートしていることから、Unity7が .Net 8をサポートするのを待っているのかもしれません。
パフォーマンス
設計意図と適用性を理解しやすくするため、パフォーマンス指標を提供します。先に記事を読んでから、後でこのパフォーマンステストに戻ってきても構いません。
8つのプロジェクトをテストしました。まず、3種類のアロケーターのパフォーマンスをテストしました:
- BenchAllocatorTemp: Allocator.Tempによる100,000回の割り当てを実行
- BenchAllocatorTempJob: 同上、アロケーターはAllocator.TempJob
- BenchAllocatorPersistent: 同上、アロケーターはAllocator.Persistent
結果はTempJobが最も速く、次にPersistentでした。
次に、4種類のJobモードのパフォーマンスをテストしました:
- BenchBaseLine: Forループで100,000回の単純計算を実行し、参考基準線とする
- BenchIJob: 100,000個のJobをスケジューリングする時間
- BenchIJobParallelFor: 並列モードで100,000個のJobをバッチスケジューリングする時間
- BenchIJobParallelForBurst: 同上、ただしBurstを有効化
- BenchIJobParallelForBurstLoopVectorization: 10個のJobをスケジューリングし、各JobでForループを用いて10,000回計算し、Burstのベクトル化を有効化
以下は私のPCでのテスト結果です:
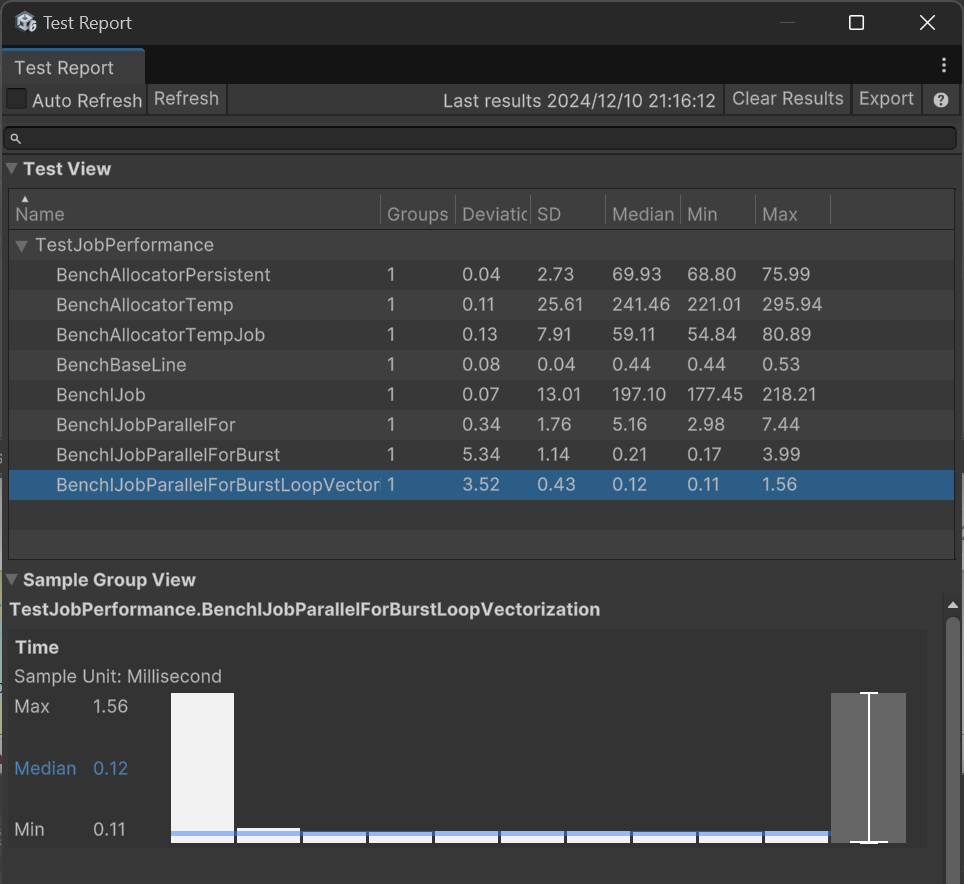
Medianはテスト項目の実行時間の中央値で、単位はミリ秒です。
Jobのスケジューリングオーバーヘッドが小さいことがわかります。これは大量のタスクを実行するために設計されているためです。もちろん、ここでは単純な乗算計算しか行っていないため、Jobによる向上は限定的です。
データ型
まず、BurstはC#のマネージド型をサポートしていません。C言語と同じ長さで、memcpy可能(シリアライゼーション/マーシャリング不要)な型、いわゆるblittable型のみ使用できます。これには基本型(intなど)が含まれます(char、string、boolは時々マネージドになるので使用しないでください)。また、blittable型の1次元Cスタイル配列(new int[5])も含まれます。Jobは必然的にBurstと組み合わせて使用するため、この制限に従います。
Unityはこのために、Job専用のスレッドセーフ型NativeArrayをラップしています。これらの型は、データポインタを渡すだけなのでコピー不要でメインスレッドとデータを共有できます。複数のコピーはすべて同じメモリ領域を参照します。派生型としてNativeList、NativeQueue、NativeHashMap、NativeHashSet、NativeTextなどがあります。
注意:nativeArray[0].x = 1.0fやnativeArray[0]++;のようなコードは使用できません。値は変更されません。なぜなら、参照ではなく値が返されるからです。
スレッドセーフティ
スレッドセーフティは、スケジューリングを制限することで実現されます。同じNativeArrayインスタンスに対して書き込みを行うJobは1つしか実行できません。そうでないと例外がスローされます。データがセグメント化によって並列化可能な場合は、IJobParallelForを使用してNativeArrayをバッチ処理できます。データが読み取り専用の場合は、メンバー変数を定義する際に[ReadOnly] public NativeArray<int> input;のように識別子を付けることができます。
Jobが書き込みを行っている間、メインスレッドはNativeArrayを読み取ることができず、エラーが発生します。完了を待つ必要があります。
メモリ割り当て(Allocate)
まず、Native型は使用後に手動でDispose()する必要があります。自動的に破棄されません。このため、Unityはメモリリークトラッキングを追加しました。
Native型をnewする際には、Temp、TempJob、Persistentの3種類のアロケーターから選択する必要があります。割り当て速度は速い順に、Tempは1フレームのライフサイクル、TempJobは4フレームです。これらは何を意味するのでしょうか?
Tempは、現在の関数内で使用し、関数終了前にDispose()することを意味します。そのため、Disposeを忘れるとUnityは次回のレンダリング時にすぐにエラーを報告します。しかし、この割り当て速度は実際には遅いです。TempJobは、より緩やかなエラー報告条件です。実際には依然として1フレーム内で使用することを想定していますが、次のフレームでDisposeすることができます。Persistentはエラーを報告しません。自分で注意する必要があります。
以前のパフォーマンステストのBenchAllocatorプロジェクトは、これら3つのパフォーマンスをテストしたものです。Allocator.Tempの所要時間がTempJobの4倍であることがわかります。ドキュメントではTempが最速とされていますが、これはバグか、エディターモードの問題のどちらかです。
シングルスレッドJobの実行
全体の流れは、自分でIJobクラスを書き、メインスレッドでそれをScheduleし、Completeを呼び出してJobの完了をブロッキング待機することです。
public struct MyJob : IJob {
public NativeArray<float> result;
public void Execute() {
for (int j = 0; j < result.Length; j++)
result[j] = result[j] * result[j];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}しかし問題は、Jobを使用するのは大量のタスクのためであり、このような単一タスクではあまり効果がありません。GPUの並列モードを参考にする方が有用です。
並列モード(Parallel Job)
上記のコードをIJobからIJobParallelForを継承するように変更するだけで並列モードになります。
public struct MyJob : IJobParallelFor {
public NativeArray<float> result;
public void Execute(int i) {
result[i] = result[i] * result[i];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule(result.Length, result.Length / 10);
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}並列モードでは自分でForループを書く必要はなく、各要素に対して1回Executeが実行されます。シェーダーに似ています。
Schedule(result.Length, result.Length / 10)は、配列の0からresult.Lengthの長さの各単位に対してExecuteを実行し、10個のワーカーに割り当てることを意味します。
IJobとIJobParallelForのパフォーマンスの違いについては、以前のパフォーマンステストを参照してください。
並列制限
IJobParallelFor内では、i要素にしか書き込めません。また、どのメンバーArrayに書き込むのかを知らないため、すべてのArrayはi要素にしか書き込めません。ただし、NativeArrayに[NativeDisableParallelForRestriction]識別子を付けてセキュリティチェックを無効にし、書き込み競合が発生しないことを自分で保証することは可能です。
読み取り専用モードでは、すべてのNativeコンテナに対して制限はありません。
また、IJobParallelForはループのベクトル化を有効にできません。計算が既にベクトル化されている場合(他のベクトル化済み関数を呼び出す場合)を除き、パフォーマンスは最適ではありません。
並列処理でのNativeListなどのコンテナの使用
Array以外のコンテナ(NativeListなど)は、並列処理では読み取り専用モードのみ可能です。では、どのように書き込むのでしょうか?
実際の設計では、NativeListはAdd操作とSet操作の2つの作業状態に分かれています。正しい使用パターンは、1つのJobでAdd操作を行い、2つ目のJobでSet操作を行うことです。
Add時にはParallelWriterとAsParallelWriterを使用できます。使用方法は以下の通りです:
public struct AddListJob : IJobParallelFor {
public NativeList<float>.ParallelWriter result;
public void Execute(int i) {
result.AddNoResize(i);
}
}
public void RunIJobParallelForList() {
var results = new NativeList<float>(10, Allocator.TempJob);
var jobData = new AddListJob() {
result = results.AsParallelWriter(),
};
var handle = jobData.Schedule(10, 1);
handle.Complete();
Debug.Log(String.Join(",", results.ToArray(Allocator.TempJob)));
results.Dispose();
}この状態では、NativeListは固定容量です。起動前にメモリを事前に確保する必要があり、AddNoResize()のみ操作できます。このメソッドは、Lengthプロパティのアトミックロックによって実現されており、パフォーマンスのオーバーヘッドが大きいです。
次に、NativeListからNativeArrayへのロスレス変換:NativeList.AsDeferredJobArray()を使用します。このメソッドが返すNativeArrayは遅延評価され、Jobが実際に実行される時点でのみ変換が行われるため、2つのJobを実行する前に渡すことができます:
var addJob = new AddListJob { result = results.AsParallelWriter() };
var jobHandle = addJob.Schedule(10, 1);
var setJob = new SetListJob { array = results.AsDeferredJobArray() };
setJob.Schedule(10, 1, jobHandle).Complete();注意:AsDeferredJobArrayまたはAsArrayが返すものはすべてビュー、つまり元データのビューです。Disposeする必要があるのは依然としてソースデータです。
二次元配列の並列モード
IJobParallelForはArrayの単一要素ごとにしか並列化できません。しかし実際には、二次元配列の各行を並列化する方が有用であり、それによってループのベクトル化を有効にでき、パフォーマンスが向上します。この操作を実行するにはIJobParallelForBatchを使用できます。
まず、[10*15]のフラットな二次元配列を作成し、IJobParallelForBatch.Schedule(int length, int batchCount)でスケジューリングします。batchCountは各jobが担当するデータ数を表し、Executeはlength/batchCount回実行されます。
var results = new NativeArray<float>(10*15, Allocator.TempJob);
var jobData = new MyJob2D {
result = results
};
var handle = jobData.Schedule(10*15, 15);
handle.Complete();
Debug.Log(String.Join(",", results));
results.Dispose();次に、MyJob2Dの実装です。
[BurstCompile]
public struct MyJob2D : IJobParallelForBatch {
public NativeArray<float> result;
public void Execute(int i, int count) {
for (int j = i; j < i + count; j++) {
result[j] = i;
}
}
}実行結果:
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,
4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,
5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,
9,9,9,9,9,9,9,9,9,9,9,9,9,9,9
UnityEngine.Debug:Log (object)この方法では、Burstが自動的にループのベクトル化を有効にするため、パフォーマンステストで100,000回の計算にかかる時間は0.09msで、最速です。
その他の制限
- Job内でJobを起動することはできません。
Asyncとの組み合わせ
上記の使用例では、UpdateでJobをスケジューリングし、LateでCompleteしています。これはUpdateコードを高速化するためです。一度限りのタスクの場合はそれほど面倒なことはせず、Async方式を使用して直接待機し、レンダリングをブロックしないようにできます。パッケージ内の拡張メソッドCompleteAsyncを使用できます:
async void GenerateMesh() {
result = new NativeArray<float>(100000, Allocator.Persistent);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
await handle.CompleteAsync();
}このモードではPersistentアロケーターを使用する必要があることに注意してください。なぜなら、必ずしも1フレーム内に完了するとは限らないからです。
Burst
BurstはLLVMベースの「高性能C#」と呼ばれるC#のサブセットであり、ほぼCコードです。通常、Monoよりも10倍から100倍高速です。もちろん、これはMonoが遅いことも示しています。
BurstはJobの実行速度をさらに向上させることができます。上記の例では、以下の1行を追加するだけです:
[BurstCompile]
public struct MyJob : IJobParallelFor {
...
}IJobParallelForのパフォーマンステストでは、この1行を追加するだけで、実行時間が5.16msから0.21msに向上し、Jobの実行速度がついにForループを超えました。
注:上記のパフォーマンステストはすべて10ワーカーでの結論です。ワーカー数を微調整するとパフォーマンス結果が異なる場合があります。
ベクトル化
ベクトル化とは、複数の計算を1つの命令にパッケージ化することです。例えば、float3の計算は自然にベクトル化されます。ベクトル化にはUnity.Mathematicsライブラリの型とメソッドを使用するのが最適です。そうでないと失敗する可能性があります。
ベクトル化計算を行っていない場合でも、ループのベクトル化を行うことができます。以前のパフォーマンステストでは、これによりさらに0.09msに向上しました。詳細は以前の二次元配列の章を参照してください。ループのベクトル化とは、並列化可能なForループ計算を1つの命令セットで完了させることであり、Burstが自動的に判断して最適化します。
Jobが正しくベクトル化されているかどうかを確認する方法
Burst Inspectorツールを開きます(Jobsメニュー内)
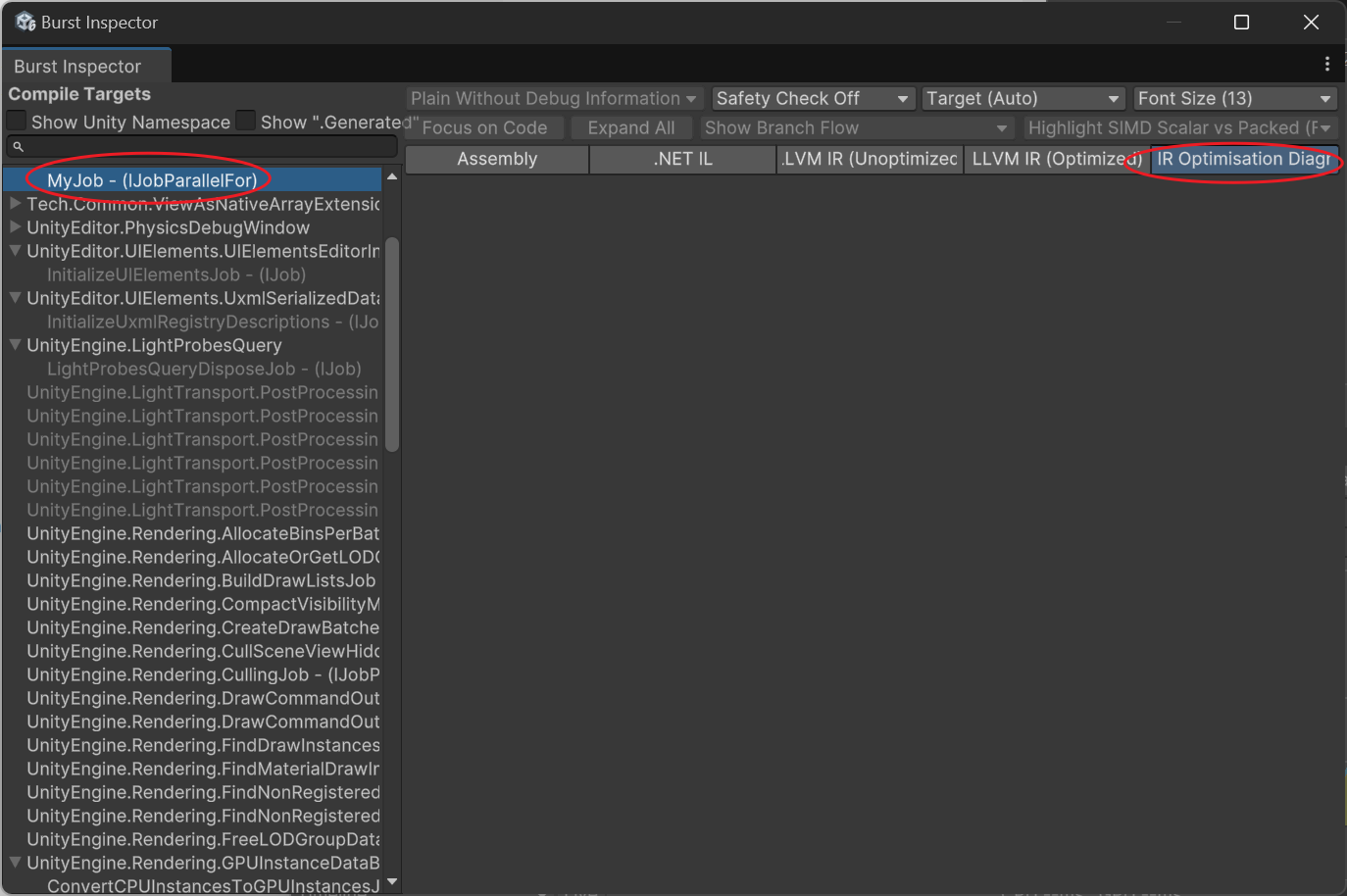
あなたの関数を選択し、Assemblyにavx命令コードがあるか、およびIR Optimisationに警告がないかを確認します。正常にベクトル化されていない場合は、以下のように表示されます:
---------------------------
Remark Type: Analysis
Message: test.cs:30:0: loop not vectorized: call instruction cannot be vectorized
Pass: loop-vectorize
Remark: CantVectorizeInstructionReturnType一般的なものは以下の通りです:
- loop not vectorized: call instruction cannot be vectorized ベクトル化できない外部関数を呼び出していることを指します。
- loop not vectorized: instruction return type cannot be vectorized 一般的にこれは既に最適化された関数を呼び出しているため、2回目のベクトル化ができないことを意味し、正常です。
JobとUnityデータの変換
JobとBurstを使用する際に最も苦痛な点の1つは、様々なデータをNativeArrayに変換することです。
例えば、Vector3をfloat3に変更する場合、同じサイズであれば直接キャストできます。例:
var floats = new NativeArray<float3>(100, Allocator.TempJob);
NativeArray<Vector3> vertices = floats.Reinterpret<Vector3>();
Vector3[] verticesArray = vertices.ToArray();
floats.Dispose();構造体にReinterpretすることもできます。例えば、3つのfloat1を1つのvector3に変換する場合:
var floats = new NativeArray<float>(new float[] {1,2,3}, Allocator.TempJob);
NativeArray<Vector3> aaa = floats.Reinterpret<Vector3>(sizeof(float));
Debug.Log(string.Join("\n", aaa.Select(v => v.ToString())));
floats.Dispose();(1.00, 2.00, 3.00)NativeArray<int>からNativeArray<ushort>へのキャストのような場合は、自分でJobを作成して変換する必要があります。
WebGLプラットフォームで自動的にバッチ実行されるJobSystem
JobSystemのコードはWebGLプラットフォームではメインスレッドで実行されるため、IJobParallelForで大量のタスクを実行するとゲームが直接フリーズします。
AdaptScheduleインターフェースを自作し、現在がWebGL環境かマルチスレッド環境かを自動的に判断できます。WebGLではworker数に応じて、1フレームずつ実行します。各ステップでyield return Awaitableを行い、メインスレッドに息継ぎの機会を与えます。
結語
Burstは実際にはコード高速化を実現するための妥協的な方法であり、これにより何でもBurst互換にしたくなる傾向が生まれ、最終的にコードは醜くなり、コンパイルも遅くなります。DOTSライブラリにもこのような痕跡が広がっています。Unityはエントロピー増大とともに本来ますます肥大化し、コンパイルはますます遅くなっています。DOTSをより大規模に適用したい場合、この問題は解決されなければなりません。
Unity7は .Net 8+とCoreCLRをサポートする予定であり、これによりEditorのコンパイル速度が向上し、 .Netの多くの新機能を利用できるようになり、Cコードとのコミュニケーションコストが減少します。少し期待して待ちましょう。おそらく将来、多くの場所でBurstを頻繁に使用する必要がなくなるかもしれません。
2月編集: CoreCLRを担当していたディレクターは意見の相違により辞任しました。皆さん、解散です。