単純および重回帰の公式とゼロからの実装
非常に短い公式であり、ESLの最初のレッスンとして、非常に基本的なものです。
これを行うことができるライブラリはたくさんありますが、ちょうど私は最近の開発で回帰のGPU計算(非常に高速化できます)が必要になったので、ついでにブログ記事を書いて、サイトの数式表示が正常かどうかをテストします。
線形回帰とは何か
簡単に言えば、線形方程式を使ってデータの傾向を表現することです。
単回帰:$y=mx+b$ 重回帰:$y=m_1x_1+m_2x_2+…+b$
 各点を同じ質量の恒星と考え、回帰線を長い棒と見立て、この重力環境下で最終的に釣り合う位置と考えることができます。
各点を同じ質量の恒星と考え、回帰線を長い棒と見立て、この重力環境下で最終的に釣り合う位置と考えることができます。
単純な単回帰の公式 (Linear regression)
Simple OLS regression を別途挙げるのは、より直感的で理解しやすいからです:
これは、共分散をxの分散で割ったものです。この公式への導出は省略しますが、この公式の魅力はすでに感じ取れたはずです。
そしてbは、mを求めた後に代入すれば得られます:
pyTorchコードによる実装
GPUによる高速化のためpyTorchを使用します。ここでは、yが2018年2月のNVDA価格データであると仮定します:
import torch
y = torch.tensor([
225.58, 228.8 , 217.52, 230.93, 228.03, 232.63, 241.42, 246.5 ,
243.84, 249.08, 241.51, 242.15, 245.93, 246.58, 246.06, 242. ,
232.21, 236.54, 235.65, 242.16
])次にxを生成します:
x = torch.arange(len(y)).float()tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15., 16., 17., 18., 19.])
回帰のコード(ここでは可読性のため、重複する計算を含みます):
demean_x = x - x.mean()
demean_y = y - y.mean()
n_1 = x.shape[0] - 1
m = torch.sum(demean_x * demean_y / n_1) / torch.sum(demean_x ** 2 / n_1)
b = y.mean() - m * x.mean()
print(m, b)(tensor(0.7734), tensor(230.4090))
グラフで効果を見てみましょう:
from matplotlib import pyplot as plt
plt.plot(x, y)
plt.plot(x, m * x + b)
plt.show()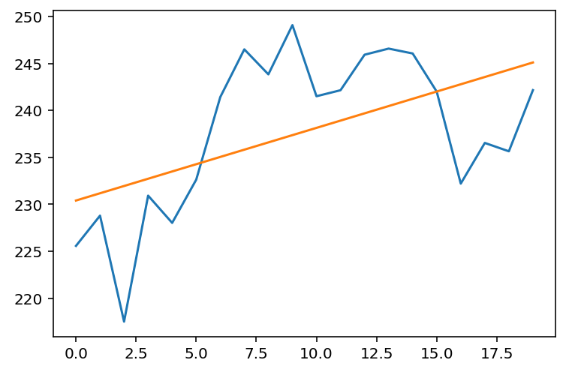 良さそうです🥂。
良さそうです🥂。
重回帰の公式(Multiple Linear regression)
本質的には単純回帰と同じで、ここでは行列表現を使用し、さらに簡潔です:
一つの公式ですべて解決します。これは単純な線形回帰にも同様に適用できます。
余談ですが、$X^TX$はあちこちで見かけます。XTXという名前のプライベートエクイティファンドもあります。
pyTorchコードによる実装
公式には多くの隠れた情報が含まれており、文章での説明は煩雑になりがちです。コードで実装してみましょう。
教科書や論文の公式には、対応するコードと各ステップの実行結果があれば、疑問点がずっと少なくなると思っています。結局のところ、コードを実行可能にするには完全な情報が必要ですから。
ここでは、二元線形回帰をデモンストレーションします。最も一般的なのは二次方程式($y=ax^2+bx+c$)を使うこと、つまり曲線フィッティングです。一元方程式なのに、なぜ二元回帰なのか? 回帰における"二元"とは、2つの独立変数:$x, x^2$を持つことを意味するからです。
引き続き上記のx, yデータを使用します。まず、X行列を生成しましょう。$x, x^2$を含みますが、ここで注意すべきは、定数1を最初の列に追加していることです。これは行列を正定値にするためと、b(図中の${\hat\beta}_0$)を求めるためです:

X = torch.stack([torch.ones(x.shape), x, x ** 2]).Ttensor([[ 1., 0., 0.], [ 1., 1., 1.], [ 1., 2., 4.], [ 1., 3., 9.], [ 1., 4., 16.], [ 1., 5., 25.], … [ 1., 15., 225.], [ 1., 16., 256.], [ 1., 17., 289.], [ 1., 18., 324.], [ 1., 19., 361.]])
そして、そのまま計算するだけです:
b, m1, m2 = (X.T @ X).inverse() @ X.T @ y
print(b, m1, m2)(tensor(220.5210), tensor(4.0694), tensor(-0.1735))
はい、これが結果です。グラフで見てみましょう:
plt.plot(x, y)
plt.plot(x, m1 * x + m2 * x**2 + b)
plt.show()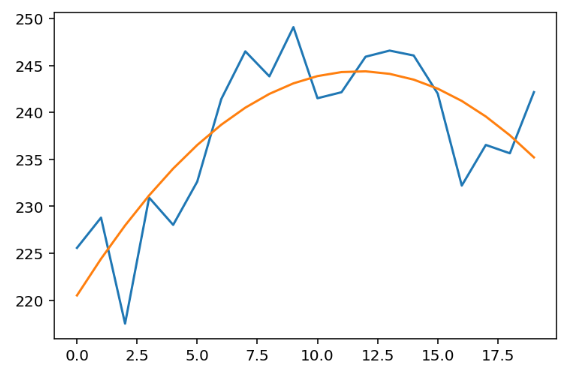
完璧です👏。とても簡単ではありませんか? しかし、実際には、複数の解や直交処理など、さらに重要な概念が後ろにあります。
多重共線性と直交性の問題
実際の使用では、単純に多項式回帰で解決できる問題はそれほど一般的ではなく、通常は観測値に対して回帰を行うことになります。そして観測値は基本的に完全に独立しているわけではなく、つまりx同士の共分散が0ではありません。 x間を独立に保つことで、係数が他のxの影響を受けずにそのxのみに責任を持つことができます。これには直交調整が必要です。
詳細には立ち入りませんが、迅速に問題を解決したい場合、ここで大まかな解決策を提供します:QR分解を使用します。Q, R = torch.qr(X) で計算した後、公式 $b, m_1,…,m_n=R^{-1}Q^Ty$ を使って解決します。
興味があれば、ESL 3.2.3 Multiple Regression from Simple Univariate Regression、つまり単回帰からの重回帰を参照してください。
著者:張戬昊 Heerozh (heerozh.com)