Tutoriel pour les débutants sur le système Unity Job et Burst : comment les utiliser correctement ?
Si le seul but est le multithreading, utiliser Async pour changer de thread ou System.Threading est la méthode la plus pratique et la plus claire. Burst peut également être appelé directement, sans nécessairement passer par Job. Voir les articles Asynchrone et Appel direct. Mais si vous avez un grand nombre de petits calculs, c’est là que vous devez envisager le système Job.
La documentation Unity Job est extrêmement incomplète. Cet article est un enregistrement d’expérience à long terme et devrait être assez complet.
Objectif et limites du Job
Contrairement à l’approche générale du multithreading, le système Unity Job est un système qui simule le haut débit du GPU via le multithreading, ce qui signifie que le coût d’allocation des tâches est extrêmement faible.
Un Job ne peut contenir que la quantité de calcul d’une seule frame, c’est un petit noyau, comme les fonctions cuda/shader. Les calculs lourds affecteront toujours les FPS, car les Jobs sont parfois attribués au thread principal pour s’exécuter. Si vous souhaitez exécuter des calculs de longue durée, soit vous les divisez en nombreux petits Jobs, sinon les threads .Net restent la meilleure option.
Alors la question se pose : puisqu’il est similaire au GPU, pourquoi ne pas utiliser directement ComputeShader ? En effet, ComputeShader peut faire tout ce que fait Job, et de manière plus pratique. Sauf si :
- Si des échanges de données fréquents avec le CPU sont nécessaires, ce que le GPU ne fait pas bien, alors Job basé sur le CPU a un avantage.
- Le système ECS (DOTS) est basé sur Job, pour la même raison.
Notez que WebGL ne supporte ni Job ni ComputeShader, ni l’accélération Burst, mais :
- WebGL est remplacé par WebGPU, qui supporte ComputeShader, et les nouveaux navigateurs le supportent déjà (IOS17 nécessite de l’activer dans les paramètres, la version 19 en aperçu l’active par défaut).
- Dans les paramètres, WebAssembly 2023 peut activer le support multithread pour Job, et le support des navigateurs est plus complet. Mais officiellement, ce n’est même pas considéré comme une fonctionnalité expérimentale, elle ne doit pas être utilisée. L’activer dans Unity6 LTS provoque un Crash. Le multithread wasm les préoccupe depuis des années, d’autant plus que DOTS est actuellement assez important, et avec .Net8 supportant le multithread wasm, peut-être attendent-ils qu’Unity7 supporte .Net8.
Performance
Fournir des indicateurs de performance permet de comprendre l’intention de conception et l’applicabilité. Vous pouvez d’abord lire l’article, puis revenir voir les tests de performance.
J’ai testé 8 projets, d’abord les performances de 3 types d’allocateurs :
- BenchAllocatorTemp : Exécute 100 000 allocations avec Allocator.Temp.
- BenchAllocatorTempJob : Idem, avec l’allocateur Allocator.TempJob.
- BenchAllocatorPersistent : Idem, avec l’allocateur Allocator.Persistent.
Le résultat est que TempJob est le plus rapide, suivi de Persistent.
Ensuite, j’ai testé les performances de 4 modes de Job :
- BenchBaseLine : Utilise une boucle For pour exécuter 100 000 calculs simples comme référence de base.
- BenchIJob : Temps de planification de 100 000 Jobs.
- BenchIJobParallelFor : Temps de planification par lots de 100 000 Jobs en mode parallèle.
- BenchIJobParallelForBurst : Idem, mais avec Burst activé.
- BenchIJobParallelForBurstLoopVectorization : Planifie 10 Jobs, chaque Job calcule 10 000 fois avec une boucle For, et active la vectorisation Burst.
Voici les résultats de mes tests sur PC :
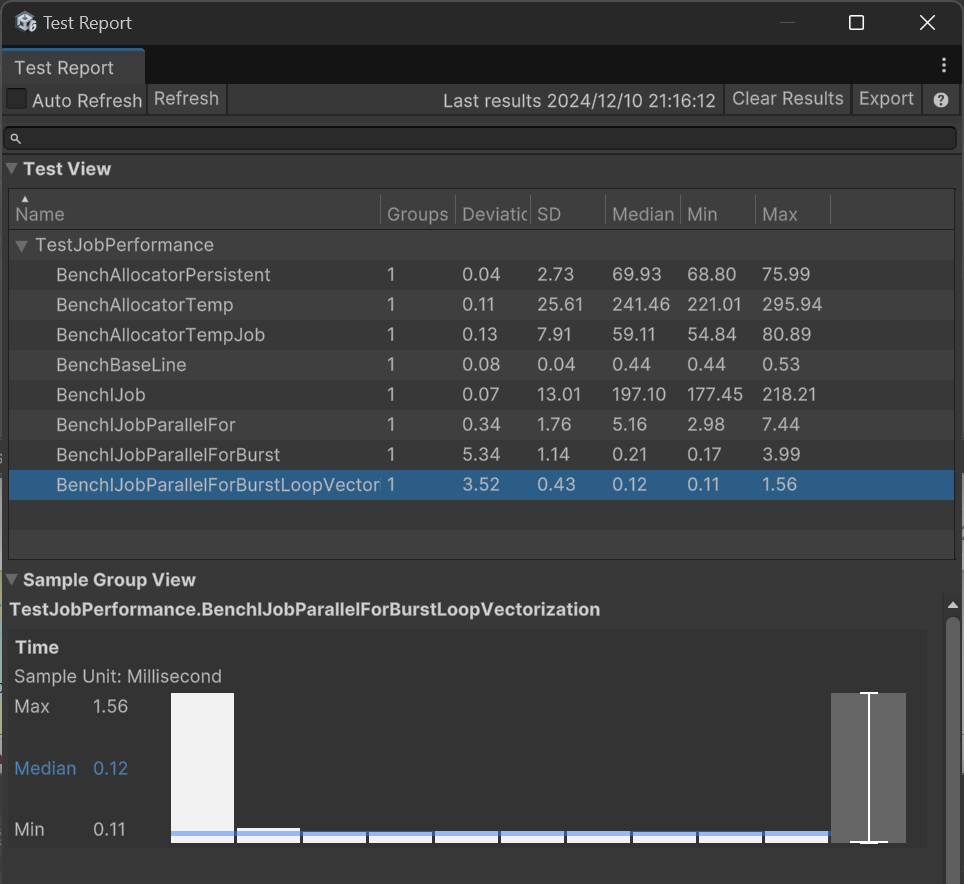
Median est la médiane du temps d’exécution du projet de test, en millisecondes.
On voit que le coût de planification des Jobs est faible, conçu pour exécuter un grand nombre de tâches. Bien sûr, je n’ai effectué ici que de simples multiplications, donc l’amélioration apportée par Job est limitée.
Types de données
Tout d’abord, Burst ne supporte pas les types managés C#, il ne peut utiliser que des types de même longueur que le C, qui peuvent être directement memcpy (pas besoin de sérialisation/marshaling), appelés blittable. Cela inclut les types de base comme int (char, string et bool sont parfois managés, ne les utilisez pas), ainsi que les tableaux C-Style unidimensionnels de types blittables (new int[5]). Et Job est nécessairement utilisé en combinaison avec Burst, donc il suit cette restriction.
Unity a encapsulé un type thread-safe NativeArray spécialement pour les Jobs. Ces types peuvent partager des données avec le thread principal sans copie, car lors de la copie, seul le pointeur de données est passé, plusieurs copies référencent la même zone mémoire. Les dérivés incluent NativeList, NativeQueue, NativeHashMap, NativeHashSet, NativeText, etc.
Attention : Vous ne pouvez pas utiliser du code comme nativeArray[0].x = 1.0f, ou nativeArray[0]++;, la valeur ne changera pas car il ne retourne pas une référence.
Sécurité des threads
La sécurité des threads est implémentée par des restrictions de planification. Une même instance de NativeArray ne peut avoir qu’un seul Job qui y écrit, sinon une exception est levée. Si les données peuvent être parallélisées par segmentation, vous pouvez utiliser IJobParallelFor pour exécuter NativeArray par lots. Si les données sont en lecture seule, vous pouvez identifier les variables membres avec par exemple [ReadOnly] public NativeArray<int> input;.
Lorsqu’un Job écrit, le thread principal ne peut pas lire NativeArray, cela générera une erreur, il faut attendre la fin.
Allocation mémoire
Tout d’abord, les types Native doivent être manuellement Dispose() après utilisation, ils ne sont pas détruits automatiquement. Pour cela, Unity a ajouté un suivi des fuites mémoire.
Lors de la création (new) d’un type Native, vous devez choisir parmi 3 types d’allocateurs : Temp, TempJob, Persistent. La vitesse d’allocation va du plus rapide au plus lent. Temp a une durée de vie d’une frame, TempJob de 4 frames. Qu’est-ce que cela signifie ?
Tempsignifie que vous l’utilisez dans la fonction actuelle, et vous devezDispose()avant la fin de la fonction. Donc si vous oubliez Dispose, Unity signalera une erreur immédiatement lors du prochain rendu. Mais cette allocation est en fait assez lente.TempJoba des conditions d’erreur plus souples. En réalité, il est toujours destiné à être utilisé dans une frame, mais vous pouvez Dispose à la frame suivante.Persistentne génère pas d’erreur, à vous d’être prudent.
Le projet BenchAllocator dans les tests de performance précédents testait les performances de ces 3. On voit que Allocator.Temp prend 4 fois plus de temps que TempJob. La documentation dit que Temp est le plus rapide, c’est soit un bug, soit un problème du mode Éditeur.
Exécuter un Job monothread
Le processus complet consiste à écrire votre propre classe IJob, à la planifier (Schedule) depuis le thread principal, puis à appeler Complete pour attendre de manière bloquante la fin du Job.
public struct MyJob : IJob {
public NativeArray<float> result;
public void Execute() {
for (int j = 0; j < result.Length; j++)
result[j] = result[j] * result[j];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}Mais le problème est que nous utilisons Job pour un grand nombre de tâches, ce type de tâche unique n’est pas très utile. Le mode parallèle, inspiré du GPU, est plus utile.
Mode parallèle (Parallel Job)
Le code ci-dessus, en changeant IJob pour hériter de IJobParallelFor, devient le mode parallèle.
public struct MyJob : IJobParallelFor {
public NativeArray<float> result;
public void Execute(int i) {
result[i] = result[i] * result[i];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule(result.Length, result.Length / 10);
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}Le mode parallèle n’écrit pas lui-même la boucle For, il exécute Execute une fois pour chaque élément, comme un Shader.
Schedule(result.Length, result.Length / 10) signifie exécuter Execute pour chaque unité de l’index 0 à result.Length, réparti sur 10 workers.
Pour la différence de performance entre IJob et IJobParallelFor, voir les tests de performance précédents.
Limitations du parallélisme
Dans IJobParallelFor, vous ne pouvez écrire que dans l’élément i, et il ne sait pas dans quel Array membre vous voulez écrire, donc tous les Arrays ne peuvent écrire que dans l’élément i. Mais vous pouvez ajouter l’attribut [NativeDisableParallelForRestriction] à NativeArray pour désactiver la vérification de sécurité, à condition de garantir vous-même l’absence de conflits d’écriture.
Le mode lecture seule n’a aucune restriction sur tous les conteneurs Native.
De plus, IJobParallelFor ne peut pas activer la vectorisation de boucle, sauf si votre calcul utilise déjà la vectorisation (appel d’autres fonctions déjà vectorisées), sinon les performances ne sont pas optimales.
Utiliser des conteneurs comme NativeList en parallèle
Les conteneurs autres que Array, comme NativeList, ne peuvent être qu’en mode lecture seule en parallèle. Alors, comment y écrire ?
En fait, par conception, NativeList est divisé en deux états de travail : Add et Set. Le bon modèle d’utilisation est qu’un Job fasse l’opération Add, et un deuxième Job fasse l’opération Set.
Pour Add, vous pouvez utiliser ParallelWriter et AsParallelWriter, voici comment :
public struct AddListJob : IJobParallelFor {
public NativeList<float>.ParallelWriter result;
public void Execute(int i) {
result.AddNoResize(i);
}
}
public void RunIJobParallelForList() {
var results = new NativeList<float>(10, Allocator.TempJob);
var jobData = new AddListJob() {
result = results.AsParallelWriter(),
};
var handle = jobData.Schedule(10, 1);
handle.Complete();
Debug.Log(String.Join(",", results.ToArray(Allocator.TempJob)));
results.Dispose();
}Dans cet état, NativeList a une capacité fixe, la mémoire doit être pré-allouée avant le démarrage, et vous ne pouvez utiliser que AddNoResize(). Cette méthode est implémentée via un verrou atomique sur la propriété Length, ce qui entraîne une perte de performance assez importante.
Ensuite, utilisez la conversion sans perte de NativeList vers NativeArray : NativeList.AsDeferredJobArray(). Cette méthode retourne un NativeArray paresseux, la conversion n’a lieu que lorsque le Job s’exécute réellement, donc il peut être passé avant l’exécution des 2 Jobs :
var addJob = new AddListJob { result = results.AsParallelWriter() };
var jobHandle = addJob.Schedule(10, 1);
var setJob = new SetListJob { array = results.AsDeferredJobArray() };
setJob.Schedule(10, 1, jobHandle).Complete();Notez que AsDeferredJobArray ou AsArray retournent tous deux une View, c’est-à-dire une vue sur les données originales. Ce qui doit être Dispose reste toujours les données sources.
Mode parallèle pour tableaux bidimensionnels
IJobParallelFor ne peut paralléliser que par élément individuel d’un Array, mais en réalité, paralléliser chaque ligne d’un tableau bidimensionnel est plus utile et peut activer la vectorisation de boucle, offrant de meilleures performances. Vous pouvez utiliser IJobParallelForBatch pour cela.
D’abord, nous créons un tableau bidimensionnel aplati [10*15], puis nous le planifions avec IJobParallelForBatch.Schedule(int length, int batchCount). batchCount indique combien de données chaque job traite, Execute sera exécuté length/batchCount fois.
var results = new NativeArray<float>(10*15, Allocator.TempJob);
var jobData = new MyJob2D {
result = results
};
var handle = jobData.Schedule(10*15, 15);
handle.Complete();
Debug.Log(String.Join(",", results));
results.Dispose();Ensuite, l’implémentation de MyJob2D.
[BurstCompile]
public struct MyJob2D : IJobParallelForBatch {
public NativeArray<float> result;
public void Execute(int i, int count) {
for (int j = i; j < i + count; j++) {
result[j] = i;
}
}
}Résultat d’exécution :
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,
4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,
5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,
9,9,9,9,9,9,9,9,9,9,9,9,9,9,9
UnityEngine.Debug:Log (object)Cette méthode peut activer automatiquement la vectorisation de boucle via Burst, donc dans les tests de performance, le temps pour 100 000 calculs était de 0,09 ms, c’est le plus rapide.
Autres limitations
- Vous ne pouvez pas lancer un Job depuis un Job.
Combinaison avec Async
L’exemple ci-dessus planifie le Job dans Update et le complète dans LateUpdate, dans le but d’accélérer le code Update. Pour une tâche ponctuelle, ce n’est pas si compliqué, vous pouvez utiliser le mode Async pour attendre directement, sans bloquer le rendu. Vous pouvez utiliser la méthode d’extension CompleteAsync du package :
async void GenerateMesh() {
result = new NativeArray<float>(100000, Allocator.Persistent);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
await handle.CompleteAsync();
}Notez que ce modèle nécessite l’allocateur Persistent, car vous ne finissez pas nécessairement en une frame.
Burst
Burst, basé sur LLVM, est un sous-ensemble du C# appelé “C# haute performance”, c’est pratiquement du code C, généralement 10 à 100 fois plus rapide que Mono, ce qui montre aussi que Mono est lent.
Burst peut encore améliorer la vitesse d’exécution des Jobs. Pour l’exemple ci-dessus, il suffit d’ajouter cette ligne :
[BurstCompile]
public struct MyJob : IJobParallelFor {
...
}Dans les tests de performance IJobParallelFor, juste avec cette ligne, le temps d’exécution passe de 5,16 ms à 0,21 ms. À ce moment, la vitesse d’exécution du Job dépasse enfin celle de la boucle For.
Note : Les tests de performance ci-dessus sont basés sur 10 Workers. Ajuster finement le nombre de Workers peut donner des résultats différents.
Vectorisation
La vectorisation consiste à regrouper plusieurs calculs en une seule instruction, par exemple les calculs float3 sont naturellement vectorisés. Pour la vectorisation, il est préférable d’utiliser les types et méthodes de la bibliothèque Unity.Mathematics, sinon cela peut échouer.
Si vous n’effectuez pas de calculs vectorisés, vous pouvez vectoriser les boucles. Les tests de performance précédents montrent une amélioration à 0,09 ms grâce à cela, voir le chapitre précédent sur les tableaux bidimensionnels. La vectorisation de boucle permet d’effectuer des calculs de boucle For parallélisables dans un seul jeu d’instructions, Burst optimise automatiquement.
Comment savoir si un Job est correctement vectorisé ?
Ouvrez l’outil Burst Inspector (dans le menu Jobs)
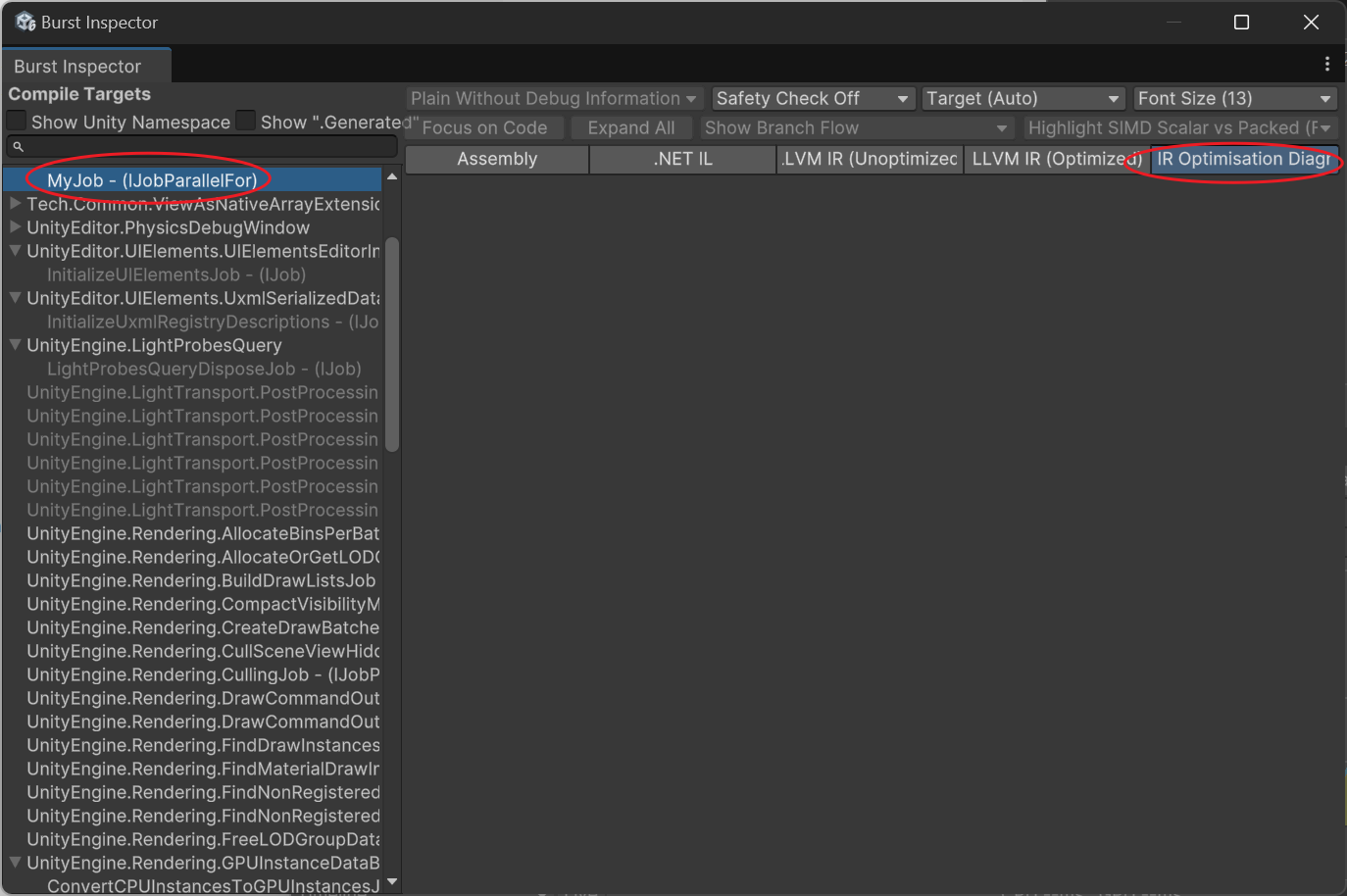
Sélectionnez votre fonction, regardez l’Assembly pour voir s’il y a du code d’instructions avx, et vérifiez les avertissements dans IR Optimisation. S’il n’est pas correctement vectorisé, cela affichera :
---------------------------
Remark Type: Analysis
Message: test.cs:30:0: loop not vectorized: call instruction cannot be vectorized
Pass: loop-vectorize
Remark: CantVectorizeInstructionReturnTypeLes cas courants sont :
- loop not vectorized: call instruction cannot be vectorized Cela signifie qu’une fonction externe non vectorisable a été appelée.
- loop not vectorized: instruction return type cannot be vectorized Généralement, c’est parce qu’une fonction déjà optimisée a été appelée, donc elle ne peut pas être vectorisée une deuxième fois, c’est normal.
Conversion entre Job et données Unity
L’un des points les plus pénibles de l’utilisation de Job et Burst est la conversion de diverses données en NativeArray.
Par exemple, Vector3 doit être changé en float3. S’ils ont la même taille, une conversion forcée directe est possible. Exemple :
var floats = new NativeArray<float3>(100, Allocator.TempJob);
NativeArray<Vector3> vertices = floats.Reinterpret<Vector3>();
Vector3[] verticesArray = vertices.ToArray();
floats.Dispose();Vous pouvez aussi Reinterpréter en structure, par exemple convertir 3 float1 en 1 vector3 :
var floats = new NativeArray<float>(new float[] {1,2,3}, Allocator.TempJob);
NativeArray<Vector3> aaa = floats.Reinterpret<Vector3>(sizeof(float));
Debug.Log(string.Join("\n", aaa.Select(v => v.ToString())));
floats.Dispose();(1.00, 2.00, 3.00)Pour les casts comme NativeArray<int> vers NativeArray<ushort>, vous devez créer votre propre Job de conversion.
JobSystem exécutant automatiquement par lots sur la plateforme WebGL
Le code JobSystem sur WebGL est exécuté par le thread principal, donc IJobParallelFor avec un grand nombre de tâches bloquera directement le jeu.
Vous pouvez créer votre propre interface AdaptSchedule pour déterminer automatiquement si l’environnement est WebGL ou multithread. Sous WebGL, exécutez étape par étape selon le nombre de worker, frame par frame. Chaque étape yield return Awaitable, permettant au thread principal de respirer.
Conclusion
Burst est en fait un moyen de compromis pour accélérer le code, ce qui entraîne une mentalité de vouloir que tout soit compatible Burst, rendant finalement le code laid et la compilation lente. La bibliothèque DOTS est également parsemée de telles traces. Unity, avec l’augmentation de l’entropie, devient de plus en plus lourd, la compilation de plus en plus lente. Pour une application à plus grande échelle de DOTS, ce problème doit être résolu.
Unity7 supportera .Net8+ et CoreCLR, ce qui augmentera la vitesse de compilation de l’Éditeur et permettra d’utiliser de nombreuses nouvelles fonctionnalités de .Net, réduisant le coût de communication avec le code C. Attendons un peu, peut-être qu’à l’avenir, beaucoup d’endroits n’auront plus besoin d’utiliser Burst aussi fréquemment.
Édition de février : Le directeur responsable de CoreCLR a démissionné en raison de divergences d’opinion, tout le monde peut se disperser.