دليل المبتدئين لنظام الوظائف (Job System) و Burst في Unity: كيفية الاستخدام الصحيح؟
إذا كان الهدف هو مجرد تعدد الخيوط (multithreading)، فإن استخدام Async لتبديل الخيوط أو System.Threading هو الطريقة الأكثر ملاءمة ووضوحًا، ويمكن استدعاء Burst مباشرة دون الحاجة بالضرورة إلى نظام الوظائف (Jobs). راجع مقالات دليل التزامن (Async) و دليل الاستدعاء المباشر. ولكن إذا كنت تتعامل مع عدد كبير من العمليات الحسابية الصغيرة، فهنا يجب أن تفكر في نظام الوظائف (Job System).
توثيق نظام الوظائف (Jobs) في Unity غير مكتمل للغاية. هذه المقالة هي تسجيل لخبرة استخدام طويلة الأمد، ويجب أن تكون شاملة إلى حد ما.
هدف نظام الوظائف (Jobs) وقيوده
على عكس نهج تعدد الخيوط التقليدي، فإن نظام الوظائف (Job System) في Unity هو نظام يحاكي الإنتاجية العالية لوحدة معالجة الرسومات (GPU) من خلال تعدد الخيوط، مما يعني أن تكلفة توزيع المهام ضئيلة للغاية.
يمكن للوظيفة (Job) أن تتحمل فقط حجم العمليات الحسابية التي تتم خلال إطار واحد (frame)، وهي نواة صغيرة مثل دوال cuda/shader. العمليات الحسابية الثقيلة ستظل تؤثر على معدل الإطارات (FPS)، لأن الوظائف (Jobs) تُعطى أحيانًا للخيط الرئيسي (main thread) للتشغيل. إذا كنت ترغب في تشغيل حسابات طويلة الأمد، فإما أن تقسمها إلى العديد من الوظائف الصغيرة (Jobs)، وإلا فإن خيوط .Net تظل الخيار الأفضل.
إذن يطرح السؤال نفسه: إذا كان النظام مشابهًا لوحدة معالجة الرسومات (GPU)، فلماذا لا نستخدم ComputeShader مباشرة؟ صحيح، كل ما تفعله الوظائف (Jobs) يمكن لـ ComputeShader القيام به، بل وأكثر ملاءمة. إلا في الحالات التالية:
- إذا كنت بحاجة إلى تبادل البيانات بشكل متكرر مع وحدة المعالجة المركزية (CPU)، وهو أمر لا تجيده وحدة معالجة الرسومات (GPU)، فإن الوظائف (Jobs) القائمة على وحدة المعالجة المركزية (CPU) تكون لها ميزة.
- نظام ECS (DOTS) يعتمد على الوظائف (Jobs)، وذلك لنفس السبب السابق.
ملاحظة: WebGL لا يدعم الوظائف (Jobs) ولا ComputeShader، ولا يدعم تسريع Burst. ولكن:
- يتم استبدال WebGL بـ WebGPU، الذي يدعم
ComputeShader، والمتصفحات الحديثة تدعمه جميعًا (في iOS 17، يجب تمكينه من الإعدادات، وفي الإصدار 19 التجريبي، يكون مفعلاً افتراضيًا). - يمكن تمكين دعم تعدد الخيوط للوظائف (Jobs) في الإعدادات عبر WebAssembly 2023، ودعم المتصفحات له أكثر شمولاً. لكن الشركة الرسمية تقول إنه لا يمكن اعتباره حتى ميزة تجريبية، ولا يمكن استخدامه. في Unity 6 LTS، سيؤدي تمكينه إلى تعطل (Crash). لقد كانوا يتجادلون حول تعدد الخيوط في wasm لسنوات عديدة، خاصة وأن DOTS يحظى حاليًا باهتمام أكبر، بالإضافة إلى دعم .Net 8 لتعدد الخيوط في wasm، ربما ينتظرون دعم Unity 7 لـ .Net 8.
الأداء
توفر مقاييس الأداء فهماً أفضل لنية التصميم وملاءمته. يمكنك قراءة المقال أولاً ثم العودة لاحقًا لمراجعة اختبارات الأداء.
تم اختبار 8 مشاريع، أولاً تم اختبار أداء 3 أنواع من المخصصات (allocators):
BenchAllocatorTemp: تنفيذ 100,000 عملية تخصيص باستخدامAllocator.TempBenchAllocatorTempJob: نفس الشيء، باستخدام مخصصAllocator.TempJobBenchAllocatorPersistent: نفس الشيء، باستخدام مخصصAllocator.Persistent
كانت النتيجة أن TempJob هي الأسرع، تليها Persistent.
ثم تم اختبار أداء 4 أنماط من الوظائف (Jobs):
BenchBaseLine: استخدام حلقةForلتنفيذ 100,000 عملية حسابية بسيطة كخط أساسي مرجعيBenchIJob: وقت جدولة 100,000 وظيفة (Job)BenchIJobParallelFor: وقت جدولة 100,000 وظيفة (Job) دفعة واحدة باستخدام الوضع المتوازيBenchIJobParallelForBurst: نفس الشيء، ولكن مع تفعيلBurstBenchIJobParallelForBurstLoopVectorization: جدولة 10 وظائف (Jobs)، كل وظيفة تحسب 10,000 مرة باستخدامFor، مع تفعيل تحسين المتجهات (vectorization) فيBurst
إليك نتائج الاختبار على جهاز الكمبيوتر الخاص بي:
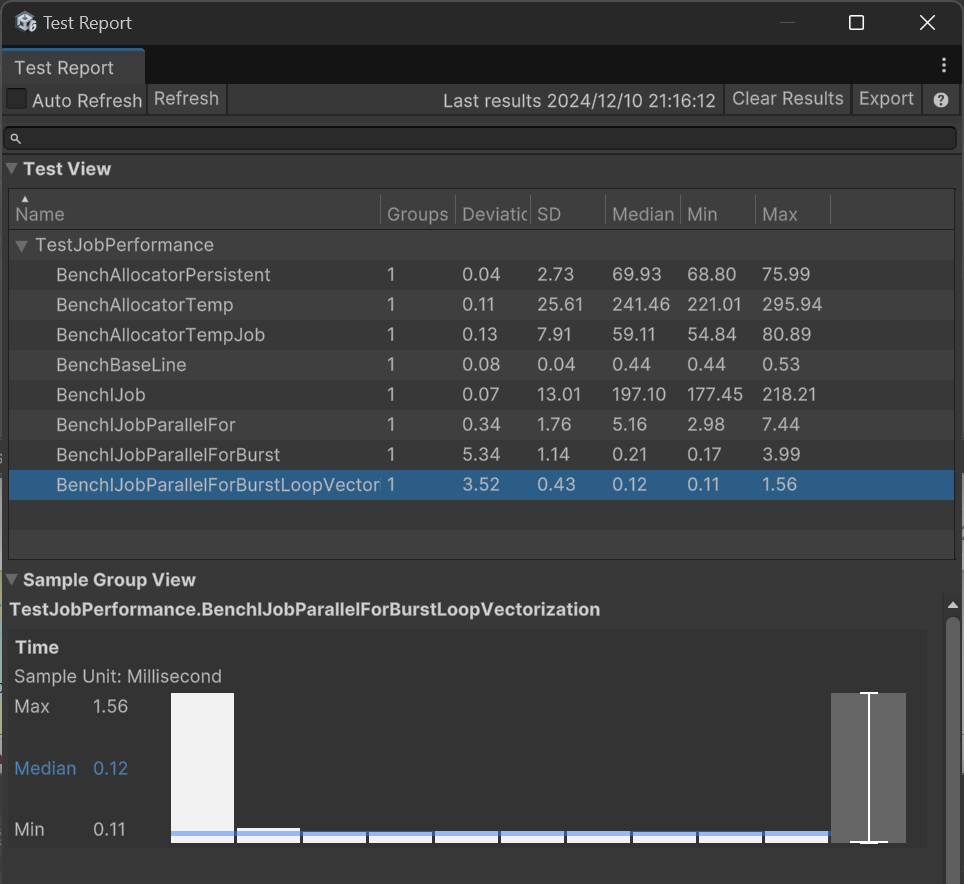
Median هو الوسيط (median) لوقت تنفيذ مشروع الاختبار، بالمللي ثانية.
من الواضح أن تكلفة جدولة الوظائف (Jobs) صغيرة، وهي مصممة لتنفيذ عدد كبير من المهام. بالطبع، لقد أجريت هنا عمليات ضرب بسيطة فقط، لذا فإن التحسين الذي تقدمه الوظائف (Jobs) محدود.
أنواع البيانات
أولاً، Burst لا يدعم أنواع C# المُدارة (managed types). يمكن استخدام الأنواع التي لها نفس طول لغة C، والتي يمكن نسخها مباشرة عبر memcpy (دون الحاجة إلى تسلسل/تجميع)، وتسمى blittable. تتضمن هذه الأنواع الأساسية مثل int وما شابه (char و string و bool قد تكون مُدارة أحيانًا، لا تستخدمها)، بالإضافة إلى مصفوفات C-Style أحادية البعد (new int[5]) من الأنواع blittable. ونظرًا لأن الوظائف (Jobs) تُستخدم حتمًا مع Burst، فإنها تتبع هذا القيد.
قام Unity بتغليف نوع آمن للخيوط يسمى NativeArray خصيصًا للاستخدام مع الوظائف (Jobs). يمكن لهذه الأنواع مشاركة البيانات مع الخيط الرئيسي دون الحاجة إلى النسخ، لأن النسخ يمرر فقط مؤشر البيانات، وتشير النسخ المتعددة إلى نفس منطقة الذاكرة. هناك أنواع مشتقة مثل NativeList، NativeQueue، NativeHashMap، NativeHashSet، NativeText، إلخ.
ملاحظة: لا يمكن استخدام كود مثل nativeArray[0].x = 1.0f، أو nativeArray[0]++;، لأن القيمة لن تتغير، لأنه لا يتم إرجاع مرجع (reference).
السلامة بين الخيوط (Thread Safety)
يتم تحقيق السلامة بين الخيوط من خلال تقييد الجدولة. يمكن لوظيفة (Job) واحدة فقط أن تكتب في نفس مثيل NativeArray، وإلا سيتم طرح استثناء. إذا كان من الممكن تحقيق التوازي من خلال تقسيم البيانات، فيمكن استخدام IJobParallelFor لتنفيذ NativeArray على دفعات. إذا كانت البيانات للقراءة فقط، فيمكن تحديد متغير العضو باستخدام، على سبيل المثال، [ReadOnly] public NativeArray<int> input; للتعريف.
عندما تكتب الوظيفة (Job)، لا يمكن للخيط الرئيسي قراءة NativeArray، وسيتم الإبلاغ عن خطأ. يجب الانتظار حتى تكتمل الوظيفة.
تخصيص الذاكرة (Allocation)
أولاً، تحتاج أنواع Native إلى التخلص منها يدويًا Dispose() بعد الانتهاء من استخدامها، فهي لا تُدمر تلقائيًا. لهذا أضاف Unity تتبع تسرب الذاكرة.
عند إنشاء نوع Native باستخدام new، يجب اختيار أحد المخصصات الثلاثة: Temp، TempJob، Persistent. تتراوح سرعة التخصيص من الأسرع إلى الأبطأ. دورة حياة Temp هي إطار واحد، و TempJob هي 4 إطارات. ماذا يعني هذا؟
Tempيعني أنه يمكنك استخدامه داخل الدالة الحالية، ويجب التخلص منهDispose()قبل انتهاء الدالة. لذلك، إذا نسيتDispose، فسيقوم Unity بالإبلاغ عن خطأ فورًا في التصيير التالي. لكن سرعة التخصيص هذه في الواقع بطيئة.TempJobيعني شروطًا أكثر تساهلاً للإبلاغ عن الخطأ. عمليًا، لا يزال يتعين عليك استخدامه خلال إطار واحد، ولكن يمكنك التخلص منهDispose()في الإطار التالي.Persistentلن يبلغ عن خطأ، وعليك أن تكون حذرًا بنفسك.
كان مشروع BenchAllocator في اختبار الأداء السابق يختبر أداء هذه الثلاثة. يمكنك أن ترى أن Allocator.Temp استغرق وقتًا أطول بأربع مرات من TempJob. يقول التوثيق أن Temp هو الأسرع، إما أن هذا خطأ (bug)، أو أنه مشكلة في وضع المحرر (Editor mode).
تنفيذ وظيفة أحادية الخيط (Single-threaded Job)
التدفق الكامل هو كتابة فئة IJob بنفسك، ثم جدولتها Schedule من الخيط الرئيسي، ثم استدعاء Complete لانتظار اكتمال الوظيفة (Job) بشكل متزامن (blocking).
public struct MyJob : IJob {
public NativeArray<float> result;
public void Execute() {
for (int j = 0; j < result.Length; j++)
result[j] = result[j] * result[j];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}لكن المشكلة هي أننا نستخدم الوظائف (Jobs) لعدد كبير من المهام. هذه المهمة الفردية ليست ذات فائدة كبيرة. نمط التوازي المشابه لوحدة معالجة الرسومات (GPU) أكثر فائدة.
النمط المتوازي (Parallel Job)
يتحول الكود أعلاه إلى النمط المتوازي بتغيير IJob إلى الوراثة من IJobParallelFor.
public struct MyJob : IJobParallelFor {
public NativeArray<float> result;
public void Execute(int i) {
result[i] = result[i] * result[i];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule(result.Length, result.Length / 10);
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}في النمط المتوازي، لا تحتاج إلى كتابة حلقة For بنفسك، حيث سيتم تنفيذ Execute مرة واحدة لكل عنصر، مشابهًا لـ Shader.
Schedule(result.Length, result.Length / 10) تعني تنفيذ Execute لكل وحدة من الفهرس 0 إلى طول result.Length، وتوزيعها على 10 عامل (worker).
للاطلاع على الفرق في الأداء بين IJob و IJobParallelFor، يمكنك مراجعة اختبار الأداء السابق.
قيود التوازي
في IJobParallelFor، يمكنك الكتابة فقط في العنصر i، وهو لا يعرف أي Array عضو تريد الكتابة فيه، لذا يمكن الكتابة فقط في العنصر i لجميع المصفوفات Array. ولكن يمكنك إضافة السمة [NativeDisableParallelForRestriction] إلى NativeArray لإيقاف فحص السلامة، والتحقق بنفسك من عدم وجود تعارض في الكتابة.
في وضع القراءة فقط، لا توجد قيود على جميع حاويات Native.
بالإضافة إلى ذلك، لا يمكن تمكين تحسين المتجهات للحلقات (loop vectorization) في IJobParallelFor، إلا إذا كانت حساباتك تستخدم بالفعل تحسين المتجهات (عن طريق استدعاء دوال أخرى تم تحسينها للمتجهات)، وإلا فلن يكون الأداء هو الأمثل.
استخدام حاويات مثل NativeList في الوضع المتوازي
جميع الحاويات بخلاف Array، مثل NativeList، تكون للقراءة فقط في الوضع المتوازي. إذن كيف يمكن الكتابة؟
في الواقع، تم تصميم NativeList ليكون لها حالتا عمل: Add و Set. نمط الاستخدام الصحيح هو أن تقوم وظيفة (Job) واحدة بعملية Add، والوظيفة الثانية بعملية Set.
عند استخدام Add، يمكن استخدام ParallelWriter و AsParallelWriter، كما يلي:
public struct AddListJob : IJobParallelFor {
public NativeList<float>.ParallelWriter result;
public void Execute(int i) {
result.AddNoResize(i);
}
}
public void RunIJobParallelForList() {
var results = new NativeList<float>(10, Allocator.TempJob);
var jobData = new AddListJob() {
result = results.AsParallelWriter(),
};
var handle = jobData.Schedule(10, 1);
handle.Complete();
Debug.Log(String.Join(",", results.ToArray(Allocator.TempJob)));
results.Dispose();
}في هذه الحالة، تكون سعة NativeList ثابتة، ويجب تخصيص الذاكرة مسبقًا قبل البدء، ويمكن فقط استخدام AddNoResize(). يتم تنفيذ هذه الطريقة من خلال قفل ذري (atomic lock) لخاصية Length، مما يسبب خسارة كبيرة في الأداء.
ثم استخدم التحويل الخالي من الخسارة من NativeList إلى NativeArray: NativeList.AsDeferredJobArray(). المصفوفة NativeArray التي تُرجعها هذه الطريقة كسولة (lazy)، حيث يتم التحويل فقط عند تشغيل الوظيفة (Job) فعليًا، لذا يمكن تمريرها قبل تنفيذ الوظيفتين (Jobs):
var addJob = new AddListJob { result = results.AsParallelWriter() };
var jobHandle = addJob.Schedule(10, 1);
var setJob = new SetListJob { array = results.AsDeferredJobArray() };
setJob.Schedule(10, 1, jobHandle).Complete(); ملاحظة: كل من AsDeferredJobArray أو AsArray يُرجعان عرضًا (View)، أي منظور للبيانات الأصلية. ما زال يجب التخلص Dispose من البيانات المصدر.
النمط المتوازي للمصفوفات ثنائية الأبعاد
يمكن لـ IJobParallelFor التوازي فقط حسب العنصر الفردي للمصفوفة Array. ولكن في الواقع، يكون التوازي لكل صف من مصفوفة ثنائية الأبعاد أكثر فائدة، ويمكنه أيضًا تمكين تحسين المتجهات للحلقات (loop vectorization)، مما يمنح أداءً أعلى. يمكن استخدام IJobParallelForBatch لتنفيذ هذه العملية.
أولاً، نقوم بإنشاء مصفوفة ثنائية الأبعاد مسطحة (flattened) بحجم [10*15]، ثم نقوم بجدولتها باستخدام IJobParallelForBatch.Schedule(int length, int batchCount). يمثل batchCount عدد البيانات التي تتحملها كل وظيفة (Job)، وسيتم تنفيذ Execute length/batchCount مرة.
var results = new NativeArray<float>(10*15, Allocator.TempJob);
var jobData = new MyJob2D {
result = results
};
var handle = jobData.Schedule(10*15, 15);
handle.Complete();
Debug.Log(String.Join(",", results));
results.Dispose();ثم يأتي تنفيذ MyJob2D.
[BurstCompile]
public struct MyJob2D : IJobParallelForBatch {
public NativeArray<float> result;
public void Execute(int i, int count) {
for (int j = i; j < i + count; j++) {
result[j] = i;
}
}
}نتيجة التنفيذ:
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,
4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,
5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,
9,9,9,9,9,9,9,9,9,9,9,9,9,9,9
UnityEngine.Debug:Log (object)يمكن لهذه الطريقة تمكين تحسين المتجهات للحلقات (loop vectorization) تلقائيًا عبر Burst، وبالتالي كان وقت حساب 100,000 مرة في اختبار الأداء هو 0.09 مللي ثانية، وهو الأسرع.
قيود أخرى
- لا يمكنك بدء وظيفة (Job) من داخل وظيفة (Job).
الدمج مع Async
في أمثلة الاستخدام أعلاه، يتم جدولة الوظيفة (Job) في Update، واستكمالها Complete في LateUpdate، بهدف تسريع كود Update. بالنسبة للمهام لمرة واحدة، لا داعي لكل هذا التعقيد، يمكنك استخدام طريقة Async للانتظار مباشرة دون تعطيل التصيير. يمكن استخدام طريقة التمديد CompleteAsync الموجودة في الحزمة:
async void GenerateMesh() {
result = new NativeArray<float>(100000, Allocator.Persistent);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
await handle.CompleteAsync();
}ملاحظة: يجب استخدام مخصص Persistent في هذا النمط، لأنك قد لا تنتهي خلال إطار واحد.
Burst
Burst، القائم على LLVM، هو مجموعة فرعية من C# تسمى “C# عالية الأداء”، وهي تقريبًا كود C، وعادة ما تكون أسرع من Mono بـ 10 إلى 100 مرة، وهذا بالطبع يدل أيضًا على أن Mono بطيء.
يمكن لـ Burst تعزيز سرعة تنفيذ الوظائف (Jobs) مرة أخرى. بالنسبة للمثال أعلاه، يكفي إضافة هذا السطر:
[BurstCompile]
public struct MyJob : IJobParallelFor {
...
}في اختبار أداء IJobParallelFor، أدت هذه السطر الواحد إلى تحسين وقت التنفيذ من 5.16 مللي ثانية إلى 0.21 مللي ثانية. عند هذه النقطة، أصبحت سرعة تنفيذ الوظائف (Jobs) أخيرًا أسرع من حلقة For.
ملاحظة: جميع نتائج اختبار الأداء أعلاه تستند إلى 10 عمال (workers). قد تختلف النتائج قليلاً عند ضبط عدد العمال.
تحسين المتجهات (Vectorization)
تحسين المتجهات هو تجميع عمليات حسابية متعددة في تعليمة واحدة. على سبيل المثال، حسابات float3 تكون محسنة للمتجهات بشكل طبيعي. من الأفضل استخدام أنواع وطرق مكتبة Unity.Mathematics لتحسين المتجهات، وإلا قد تفشل.
إذا لم تقم بإجراء حسابات محسنة للمتجهات، يمكنك أيضًا تحسين المتجهات للحلقات (loop vectorization)، مما أدى في اختبار الأداء السابق إلى تحسين آخر إلى 0.09 مللي ثانية، كما هو موضح في الفصل السابق حول المصفوفات ثنائية الأبعاد. تحسين المتجهات للحلقات يعني إكمال بعض حسابات For التي يمكن توازيها داخل مجموعة تعليمات واحدة، وسيقوم Burst بالتحسين تلقائيًا بعد الحكم عليها.
كيف تعرف إذا كانت الوظيفة (Job) محسنة للمتجهات بشكل صحيح؟
افتح أداة Burst Inspector (في قائمة Jobs)
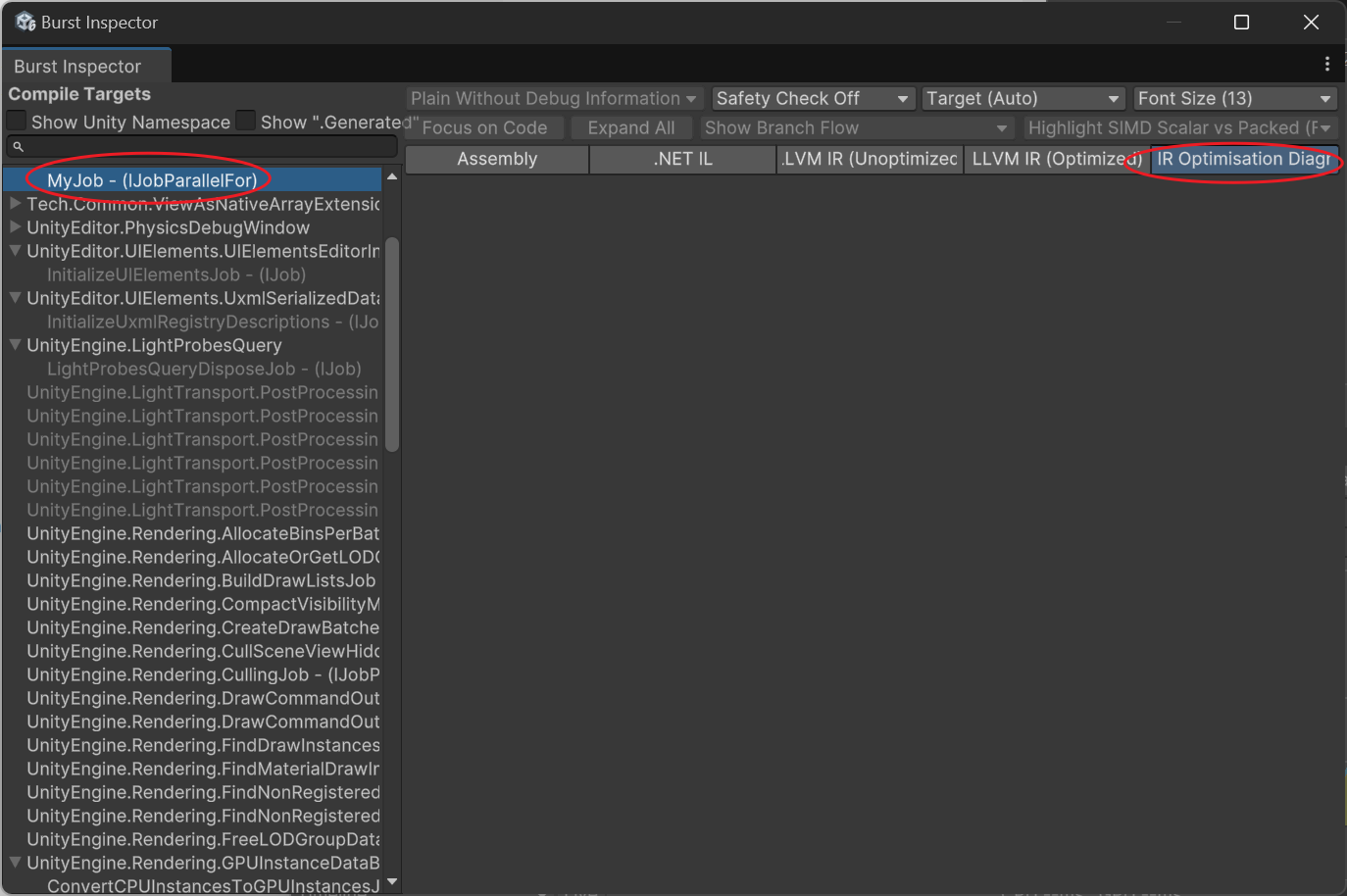
حدد الدالة الخاصة بك، وتحقق مما إذا كان كود التجميع (Assembly) يحتوي على تعليمات avx، وتحقق مما إذا كان هناك تحذيرات في IR Optimisation. إذا لم يتم تحسين المتجهات بشكل صحيح، فسيظهر:
---------------------------
Remark Type: Analysis
Message: test.cs:30:0: loop not vectorized: call instruction cannot be vectorized
Pass: loop-vectorize
Remark: CantVectorizeInstructionReturnTypeمن الشائع:
loop not vectorized: call instruction cannot be vectorizedيشير إلى استدعاء دالة خارجية لا يمكن تحسينها للمتجهات.loop not vectorized: instruction return type cannot be vectorizedعادةً ما يكون هذا بسبب استدعاء دالة تم تحسينها بالفعل، وبالتالي لا يمكن تحسينها للمتجهات مرة ثانية، وهذا طبيعي.
تحويل البيانات بين الوظائف (Jobs) وبيانات Unity
أكثر نقطة مؤلمة في استخدام الوظائف (Jobs) و Burst هي تحويل أنواع البيانات المختلفة إلى NativeArray.
على سبيل المثال، يجب تغيير Vector3 إلى float3. إذا كان الحجم متساويًا، فيمكن التحويل مباشرة عن طريق الإعادة التفسير (reinterpret). مثال:
var floats = new NativeArray<float3>(100, Allocator.TempJob);
NativeArray<Vector3> vertices = floats.Reinterpret<Vector3>();
Vector3[] verticesArray = vertices.ToArray();
floats.Dispose();يمكن أيضًا إعادة التفسير إلى هيكل (struct)، مثل تحويل 3 عناصر float1 إلى vector3 واحد:
var floats = new NativeArray<float>(new float[] {1,2,3}, Allocator.TempJob);
NativeArray<Vector3> aaa = floats.Reinterpret<Vector3>(sizeof(float));
Debug.Log(string.Join("\n", aaa.Select(v => v.ToString())));
floats.Dispose();(1.00, 2.00, 3.00)للتحويلات مثل NativeArray<int> إلى NativeArray<ushort>، والتي تتطلب تحويل نوع (cast)، فأنت بحاجة إلى إنشاء وظيفة (Job) للتحويل بنفسك.
JobSystem الذي ينفذ تلقائيًا على دفعات على منصة WebGL
سيتم تنفيذ كود JobSystem على منصة WebGL بواسطة الخيط الرئيسي، لذا فإن عددًا كبيرًا من المهام في IJobParallelFor سيتسبب في تعطل اللعبة مباشرة.
يمكنك إنشاء واجهة AdaptSchedule بنفسك، لتحديد تلقائيًا ما إذا كانت البيئة الحالية هي WebGL أم بيئة متعددة الخيوط. في حالة WebGL، سيتم التنفيذ إطارًا تلو الآخر حسب عدد العمال (workers). في كل خطوة، سيقوم yield بإرجاع Awaitable، لإعطاء الخيط الرئيسي فرصة للتنفس.
خاتمة
Burst هو في الواقع طريقة تسوية (compromise) لتحسين سرعة الكود، وهذا يخلق عقلية الرغبة في توافق كل شيء مع Burst، مما يؤدي في النهاية إلى كود قبيح وتجميع أبطأ، وتنتشر آثار ذلك في مكتبة DOTS. مع زيادة الإنتروبيا (entropy)، أصبح Unity أكثر تعقيدًا وأبطأ في التجميع. لتحقيق تطبيق أوسع نطاقًا لـ DOTS، يجب حل هذه المشكلة.
سيقوم Unity 7 بدعم .Net8+ و CoreCLR، مما سيزيد من سرعة تجميع المحرر (Editor)، وسيمكن من استخدام العديد من الميزات الجديدة في .Net، ويقلل من تكلفة التواصل مع كود C. دعونا نتطلع قليلاً إلى المستقبل، حيث ربما لن نحتاج إلى استخدام Burst بشكل متكرر في العديد من الأماكن.
تحرير فبراير: استقال المدير المسؤول عن CoreCLR بسبب خلاف في الرأي، انفضوا جميعًا.