如果单就多线程目的,使用Async切换线程或System.Threading是最方便和清晰的方法,Burst也可以直接调用,并不一定需要Job,见异步篇和直接调用篇文章。但如果是大量小运算,此时你才需要考虑Job系统。
Unity Job文档极其不全,本文为长期使用经验记录,应该较为全面。
Job的目的和限制
不同于一般多线程思路,Unity Job系统是一种通过多线程模拟GPU高吞吐量的系统,也就是说分配任务开销极小。
Job只能承载1帧内的运算量,和cuda/shader的函数一样是小内核。繁重运算依然会影响FPS,因为Job有时会分配给主线程运行。如果你希望运行长时间的计算,要么拆成很多小Job,不然.Net线程还是最好的。
那么问题来了,既然是类似GPU,为啥不直接用ComputeShader?没错,Job的工作ComputeShader都能做,而且更方便。除非:
- 如果需要频繁和CPU交换数据,GPU不擅长此事,基于CPU的Job就有优势了
- ECS(DOTS)系统是基于Job的,原因同上
注意,WebGL不支持Job和ComputeShader,也不支持Burst加速,但:
- WebGL在被WebGPU替代,WebGPU支持ComputeShader,且新版浏览器都已支持(IOS17需要设置中开启,19预览已默认开启)。
- 设置里WebAssembly 2023可以开启多线程支持Job,且浏览器支持更全面。但官方说连实验性功能都算不上,不可使用,Unity6 LTS开启会Crash。wasm多线程让他们纠结很多年了,况且目前DOTS比较被重视,加上.Net8支持wasm多线程,也许他们在等Unity7支持.Net8。
性能
提供性能指标可以方便理解设计意图和适用性,你也可以先看文章再回头过来看性能测试。
测试了8个项目,先是测试了3种分配器的性能:
- BenchAllocatorTemp: 执行100,000次Allocator.Temp分配
- BenchAllocatorTempJob:同上,分配器Allocator.TempJob
- BenchAllocatorPersistent:同上,分配器Allocator.Persistent
结果是TempJob最快,其次Persistent。
然后测试4种Job模式的性能:
- BenchBaseLine:用For执行100,000次简单计算作为参考基准线
- BenchIJob:排程100,000次Job的时间
- BenchIJobParallelFor:用并行模式批量排程100,000次Job的时间
- BenchIJobParallelForBurst:同上,但打开Burst
- BenchIJobParallelForBurstLoopVectorization:排程10个Job,每个Job用For计算10,000次,并打开Burst向量化
以下是我PC测试效果:
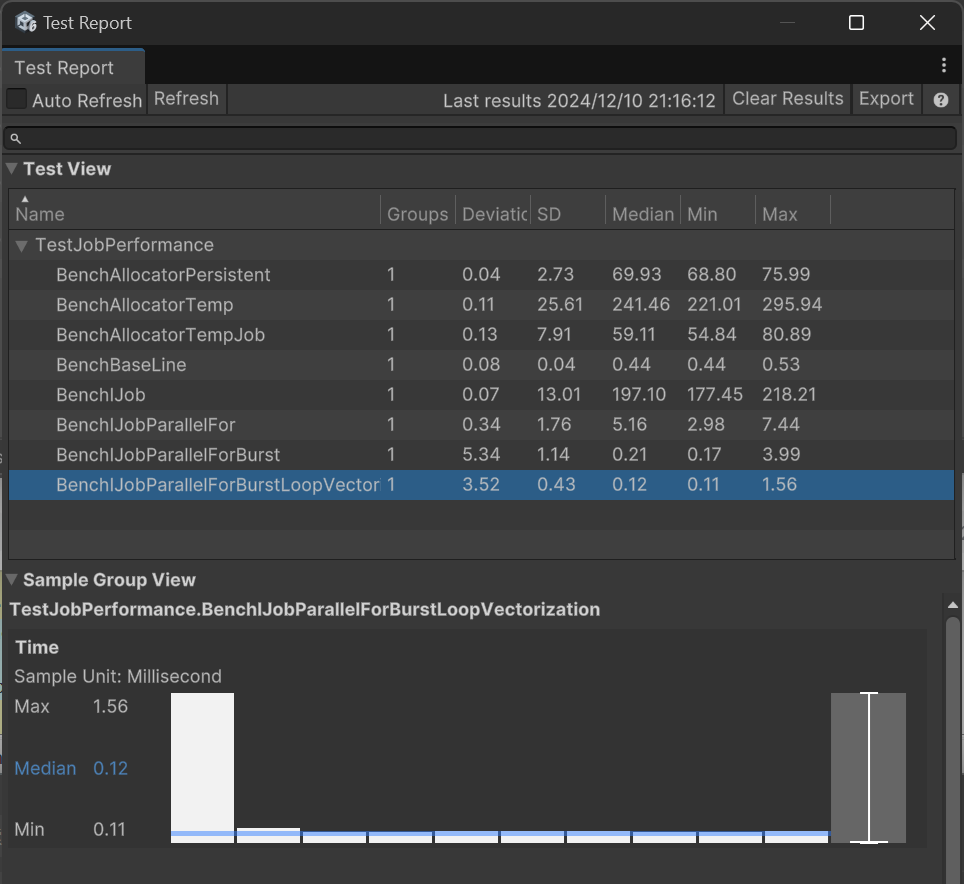
Median就是测试项目耗时中位数,单位毫秒。
可见Job排程开销小,是为了执行大量任务设计的。当然我这里只进行了简单的乘法计算,所以Job提升有限。
数据类型
首先Burst不支持C#托管类型,只能用和C一样长度的,可以直接memcpy(无需序列化编组)的类型,叫blittable,包含基本类型int等(char, string和bool则有时是托管的,别用),以及blittable类型的1维C-Style array(new int[5])。而Job必然和Burst组合使用,所以跟着此限制。
Unity为此封装了个NativeArray线程安全类型,专为Job使用。这些类型可和主线程共享数据无需Copy,因为复制时只会pass数据指针,多个副本都引用相同的内存区域。衍生的有NativeList,NativeQueue,NativeHashMap,NativeHashSet,NativeText等,但这些只能在单线程中使用。
注意:不能用nativeArray[0].x = 1.0f,或nativeArray[0]++;这种代码,值不会变,因为他返回的不是引用。
线程安全
线程安全通过限制调度实现,同一个NativeArray实列只能执行1个Job对其写入,不然会抛出异常。如果数据可以通过分段实现并行,可以用IJobParallelFor对NativeArray分批执行。如果是只读数据,可以定义成员变量时用比如[ReadOnly] public NativeArray<int> input;来标识。
Job写入时,主线程不能对NativeArray读取,会报错,要等待完成。
内存调配(allocate)
首先,Native类型使用完需要你手动Dispose(),并不会自动销毁,为此Unity增加了内存泄漏跟踪。
Native类型new时需要选择Temp,TempJob,Persistent3种类型分配器,分配速度从快到慢,Temp 1帧生命周期,TempJob 4帧,这些什么意思呢?
Temp意思就是给你在当前函数内用,函数结束前就Dispose(),因此忘了Dispose后Unity下次渲染立即就会报错,但这个分配速度其实很慢TempJob就是较为宽松的报错条件,实际还是让你在1帧内用,只是可以在下一帧DisposePersistent不会报错,要你自己小心
之前性能测试的BenchAllocator项目就是测试这3个的性能,可以看到Allocator.Temp耗时反而是TempJob 4倍,文档说Temp是最快的,这要么BUG,要么就是Editor模式问题。
执行单线程Job
整个流程就是自己写个IJob类,主线程Schedule它,然后调用Complete堵塞等待Job完成。
public struct MyJob : IJob {
public NativeArray<float> result;
public void Execute() {
for (int j = 0; j < result.Length; j++)
result[j] = result[j] * result[j];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}
但问题是,我们用Job就是为了大量任务,这种单个任务的作用不大。参考GPU的并行模式更有用。
并行模式(Parallel Job)
上述代码从IJob改为继承IJobParallelFor就是并行模式了。
public struct MyJob : IJobParallelFor {
public NativeArray<float> result;
public void Execute(int i) {
result[i] = result[i] * result[i];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule(result.Length, result.Length / 10);
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}
并行模式不用自己写For loop,会对每个元素执行一次Execute,类似Shader。
Schedule(result.Length, result.Length / 10)指的是对数组0到result.Length长度的每个单位执行Execute,分配到10个worker上。
关于IJob和IJobParallelFor的性能区别可以看之前的性能测试。
并行限制
在IJobParallelFor中你只能写入i元素,而且它并不知道你要写入哪一个成员Array,所以所有Array都只能写i元素,但可以给NativeArray加上[NativeDisableParallelForRestriction]标识关闭安全检查,自己保证无写入冲突即可。
只读模式则对所有的Native容器都没有限制。
另外IJobParallelFor无法开启循环向量化,除非你的计算已经使用了向量化(调用其他已被向量化的函数),不然性能仍然不是最优的。
在并行中使用NativeList等容器
Array以外的容器如NativeList并行下都只能只读模式,那么要如何写入呢?
其实设计上NativeList分为了Add和Set二种工作状态,正确的使用模式是,一个Job做Add操作,第二个Job做Set操作。
Add时可以使用ParallelWriter和AsParallelWriter,用法如下:
public struct AddListJob : IJobParallelFor {
public NativeList<float>.ParallelWriter result;
public void Execute(int i) {
result.AddNoResize(i);
}
}
public void RunIJobParallelForList() {
var results = new NativeList<float>(10, Allocator.TempJob);
var jobData = new AddListJob() {
result = results.AsParallelWriter(),
};
var handle = jobData.Schedule(10, 1);
handle.Complete();
Debug.Log(String.Join(",", results.ToArray(Allocator.TempJob)));
results.Dispose();
}
此状态下NativeList是固定容量的,启动前必须预申请内存,并且只能操作AddNoResize()。该方法通过原子锁Length属性实现,性能损耗挺大。
然后使用NativeList到NativeArray的无损转换:NativeList.AsDeferredJobArray(),该方法返回的NativeArray是懒惰的,只在Job实际运行时才进行转换,所以可以在2个Job执行前就传入:
var addJob = new AddListJob { result = results.AsParallelWriter() };
var jobHandle = addJob.Schedule(10, 1);
var setJob = new SetListJob { array = results.AsDeferredJobArray() };
setJob.Schedule(10, 1, jobHandle).Complete();
注意AsDeferredJobArray或者AsArray返回的都是View,也就是原数据的视图。必须Dispose的依然是源数据。
二维数组的并行模式
IJobParallelFor只能按Array的单个元素并行,但实际上对二维数组的每一行并行有更有用,还能因此启用循环向量化,性能更高。可使用IJobParallelForBatch来执行此操作。
首先我们创建了一个[10*15]的平铺二维数组,然后通过IJobParallelForBatch.Schedule(int length, int batchCount)来排程,batchCount表示每个job负责多少个数据,Execute会被执行length/batchCount次。
var results = new NativeArray<float>(10*15, Allocator.TempJob);
var jobData = new MyJob2D {
result = results
};
var handle = jobData.Schedule(10*15, 15);
handle.Complete();
Debug.Log(String.Join(",", results));
results.Dispose();
然后是MyJob2D的实现。
[BurstCompile]
public struct MyJob2D : IJobParallelForBatch {
public NativeArray<float> result;
public void Execute(int i, int count) {
for (int j = i; j < i + count; j++) {
result[j] = i;
}
}
}
执行结果:
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,
4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,
5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,
9,9,9,9,9,9,9,9,9,9,9,9,9,9,9
UnityEngine.Debug:Log (object)
此方法可以通过Burst自动启用循环向量化,因此性能测试中计算100,000次的时间是0.09ms,是最快的。
其他限制
- 你不能在Job中启动Job。
和Async结合
上述用例在Update中排程Job,在Late里Complete,目的是为了加速Update代码,对于一次性任务不用那么麻烦,可以用Async方式直接等待,且不卡渲染。可用包里的扩展方法CompleteAsync:
async void GenerateMesh() {
result = new NativeArray<float>(100000, Allocator.Persistent);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
await handle.CompleteAsync();
}
注意此模式要用Persistent分配器,因为你并不一定在1帧内完成。
Burst
Burst基于LLVM是称为“高性能 C#”的 C# 子集,差不多就是C代码,通常比Mono快10到100倍,当然这也说明Mono慢。
Burst可以再次增强Job的执行速度,对于上述示例,只要加一行这个:
[BurstCompile]
public struct MyJob : IJobParallelFor {
...
}
``IJobParallelFor`的性能测试仅通过这行,执行时间就能从5.16ms提升到0.21ms,此时Job执行速度终于超过For循环。
注:以上性能测试都是用10个Worker的结论,微调Worker数性能结果可能有不同
向量化
向量化就是把多个计算打包成1个指令,比如float3的计算天然就是向量化的。向量化最好使用Unity.Mathematics库的类型和方法,不然可能失败。
如果你没有进行向量化计算,还可以对循环向量化,之前的性能测试可因此再提升到0.09ms,见之前关于二维数组的章节。循环向量化就是让一些可以并行的For loop计算,在一个指令集中完成,Burst会自动判断优化。
如何知道Job是否正确向量化了?
打开Burst Inspector工具(在Jobs菜单里)
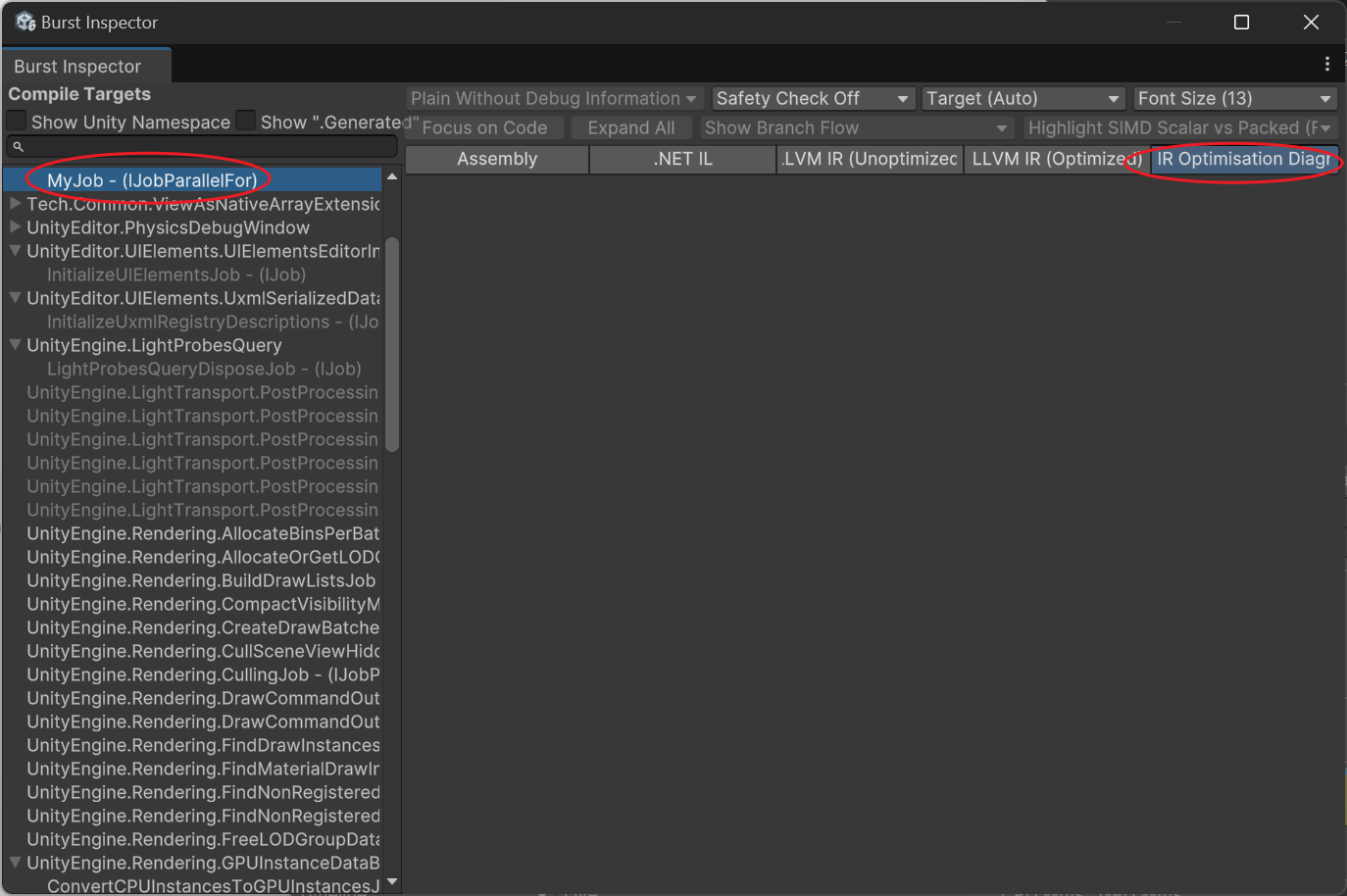
选中你的函数,看Assembly是否有avx指令代码,以及看IR Optimisation是否有警告。如果未正常向量化,会显示:
---------------------------
Remark Type: Analysis
Message: test.cs:30:0: loop not vectorized: call instruction cannot be vectorized
Pass: loop-vectorize
Remark: CantVectorizeInstructionReturnType
常见的有:
- loop not vectorized: call instruction cannot be vectorized
是指调用了无法向量化的外部函数。 - loop not vectorized: instruction return type cannot be vectorized
一般这是调用了已经优化的函数,因此无法向量化第二遍,是正常的。
Job和Unity数据的转换
用Job和Burst最痛苦的一点是各种数据要转换到NativeArray。
比如Vector3要改成float3,同尺寸是可以直接强制转换的。示例:
var floats = new NativeArray<float3>(100, Allocator.TempJob);
NativeArray<Vector3> vertices = floats.Reinterpret<Vector3>();
Vector3[] verticesArray = vertices.ToArray();
floats.Dispose();
也可以Reinterpret成结构,比如把3个float1转换成1个vector3:
var floats = new NativeArray<float>(new float[] {1,2,3}, Allocator.TempJob);
NativeArray<Vector3> aaa = floats.Reinterpret<Vector3>(sizeof(float));
Debug.Log(string.Join("\n", aaa.Select(v => v.ToString())));
floats.Dispose();
(1.00, 2.00, 3.00)
对于像NativeArray<int>转换到NativeArray<ushort>这种cast,则需要自己建立Job转换。
在WebGL平台自动分批执行的JobSystem
JobSystem的代码在WebGL平台上会由主线程执行,所以IJobParallelFor大量任务会直接卡死游戏。
这里提供一个AdaptSchedule接口,自动判断现在是WebGL环境,还是多线程环境。WebGL下按worker数,一帧帧执行。每一步会yield return Awaitable,让主线程获得喘息,代码如下:
MyJob jobData = new MyJob{
result = result
};
await jobData.AdaptSchedule(result.Length, result.Length / 64);
以上代码在WebGL中将分64帧执行,在其他多线程环境则由64个Worker执行。
结语
Burst其实是一种妥协的方式实现代码加速,这也带来了一种写啥都想要Burst兼容的心态,最终代码丑陋,编译还慢,DOTS库中也遍布此类痕迹。Unity随着熵增本来就越来越臃肿,编译越来越慢,想要DOTS更大规模的应用,此问题必须得到解决。
Unity7会支持.Net8+和CoreCLR,这会增加Editor的编译速度,也可以用到.Net的很多新特性,减少和C代码沟通的成本,让我们稍微期待下,也许未来很多地方不需要那么频繁的使用Burst了。
2月编辑:
负责CoreCLR的总监因为意见分歧已辞职,大家散了散了。