Formules et implémentation de zéro pour la régression linéaire simple et multiple
Ce sont des formules très courtes, et en tant que première leçon d’ESL, elles sont très fondamentales.
De nombreuses bibliothèques peuvent faire cela, mais il se trouve que j’ai récemment eu besoin d’utiliser le GPU pour calculer la régression dans mon développement (ce qui peut accélérer les calculs de plusieurs fois), alors j’en profite pour écrire un article de blog pour tester si l’affichage des formules sur le site fonctionne correctement.
Qu’est-ce que la régression linéaire
En termes simples, il s’agit d’utiliser une équation linéaire pour représenter la tendance des données.
Une variable : $y=mx+b$ Variables multiples : $y=m_1x_1+m_2x_2+…+b$
 Vous pouvez imaginer que chaque point est une étoile de même masse, et la droite de régression est comme placer une longue tige qui finit par trouver sa position d’équilibre dans cet environnement gravitationnel.
Vous pouvez imaginer que chaque point est une étoile de même masse, et la droite de régression est comme placer une longue tige qui finit par trouver sa position d’équilibre dans cet environnement gravitationnel.
Formule de régression linéaire simple (Linear regression)
La régression OLS simple est présentée séparément car elle est plus intuitive et facile à comprendre :
C’est simplement la covariance divisée par la variance de x. Nous ne détaillerons pas la dérivation de cette formule, mais vous devriez déjà en ressentir l’élégance.
Ensuite, b s’obtient en substituant m :
Implémentation en code pyTorch
Nous utilisons pyTorch pour l’accélération GPU. Supposons que nous ayons des données de prix NVDA pour février 2018 dans y :
import torch
y = torch.tensor([
225.58, 228.8 , 217.52, 230.93, 228.03, 232.63, 241.42, 246.5 ,
243.84, 249.08, 241.51, 242.15, 245.93, 246.58, 246.06, 242. ,
232.21, 236.54, 235.65, 242.16
])Ensuite, nous générons x :
x = torch.arange(len(y)).float()tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15., 16., 17., 18., 19.])
Code de régression (ici, pour la lisibilité, certains calculs sont répétés) :
demean_x = x - x.mean()
demean_y = y - y.mean()
n_1 = x.shape[0] - 1
m = torch.sum(demean_x * demean_y / n_1) / torch.sum(demean_x ** 2 / n_1)
b = y.mean() - m * x.mean()
print(m, b)(tensor(0.7734), tensor(230.4090))
Visualisons le résultat :
from matplotlib import pyplot as plt
plt.plot(x, y)
plt.plot(x, m * x + b)
plt.show()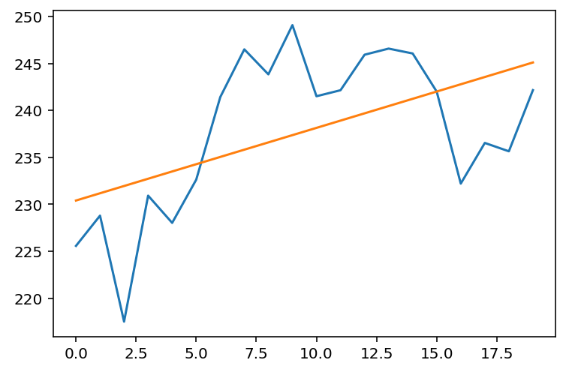 Ça a l’air bien 🥂.
Ça a l’air bien 🥂.
Formule de régression linéaire multiple (Multiple Linear regression)
L’essence est la même que pour la régression simple. Ici, nous utilisons une expression matricielle, encore plus concise :
Une seule formule résout tout, et elle s’applique également à la régression linéaire simple.
En aparté, $X^TX$ apparaît partout, et il existe même un fonds d’investissement privé qui s’appelle XTX.
Implémentation en code pyTorch
La formule contient beaucoup d’informations cachées, et une explication textuelle serait trop fastidieuse. Implémentons-la avec du code.
J’ai toujours pensé que si les formules des manuels et des articles de recherche étaient accompagnées de code correspondant et des résultats de chaque étape, il y aurait beaucoup moins d’interrogations à la lecture, car le code exécutable nécessite des informations complètes.
Nous utiliserons ici une régression linéaire à deux variables pour la démonstration. L’exemple le plus courant est l’utilisation d’une équation quadratique ($y=ax^2+bx+c$), c’est-à-dire l’ajustement d’une courbe. Puisqu’il s’agit d’une équation à une variable, pourquoi une régression à deux variables ? Parce que les deux variables de la régression font référence aux 2 variables indépendantes : $x, x^2$
En utilisant toujours les données x, y ci-dessus, commençons par générer la matrice X, contenant $x, x^2$. Notez cependant que la première colonne inclut une constante 1, pour assurer la définition positive de la matrice et calculer b (représenté par ${\hat\beta}_0$ dans la figure) :

X = torch.stack([torch.ones(x.shape), x, x ** 2]).Ttensor([[ 1., 0., 0.], [ 1., 1., 1.], [ 1., 2., 4.], [ 1., 3., 9.], [ 1., 4., 16.], [ 1., 5., 25.], … [ 1., 15., 225.], [ 1., 16., 256.], [ 1., 17., 289.], [ 1., 18., 324.], [ 1., 19., 361.]])
Ensuite, il suffit de calculer directement :
b, m1, m2 = (X.T @ X).inverse() @ X.T @ y
print(b, m1, m2)(tensor(220.5210), tensor(4.0694), tensor(-0.1735))
Oui, c’est le résultat. Visualisons-le :
plt.plot(x, y)
plt.plot(x, m1 * x + m2 * x**2 + b)
plt.show()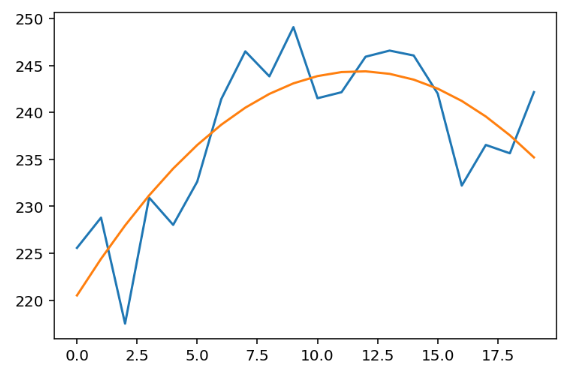
Parfait 👏. N’est-ce pas simple ? Mais il y a en réalité des concepts plus importants derrière, comme les cas de solutions multiples et l’orthogonalisation.
Colinéarité et problème d’orthogonalité
Dans la pratique, les problèmes pouvant être résolus par une simple régression polynomiale ne sont pas courants. Généralement, il s’agit de régresser sur des valeurs observées, et ces observations ne sont presque jamais totalement indépendantes, c’est-à-dire que la covariance entre les x n’est pas nulle. Maintenir l’indépendance entre les x permet que chaque coefficient ne soit responsable que de son x sans être influencé par les autres, ce qui nécessite un ajustement orthogonal.
Je ne vais pas entrer dans les détails. Si vous voulez résoudre le problème rapidement, voici une solution approximative : utilisez la décomposition QR. Calculez avec Q, R = torch.qr(X), puis utilisez la formule $b, m_1,…,m_n=R^{-1}Q^Ty$ pour résoudre.
Si vous êtes intéressé, vous pouvez consulter ESL 3.2.3 Multiple Regression from Simple Univariate Regression, qui utilise la régression univariée pour la régression multiple.
Auteur : Zhang Jianhao Heerozh (heerozh.com)

1700515