Unity Job-System und Burst für Dummies: Wie verwendet man sie richtig?
Wenn es nur um Multithreading geht, sind Async zum Threadwechsel oder System.Threading die bequemsten und klarsten Methoden. Burst kann auch direkt aufgerufen werden und benötigt nicht unbedingt Jobs. Siehe die Artikel Asynchroner Teil und Direkter Aufruf. Aber wenn es um viele kleine Berechnungen geht, dann sollte man das Job-System in Betracht ziehen.
Die Unity Job-Dokumentation ist extrem unvollständig. Dieser Artikel basiert auf langjähriger Erfahrung und sollte recht umfassend sein.
Zweck und Einschränkungen von Jobs
Im Gegensatz zum allgemeinen Multithreading-Ansatz ist das Unity Job-System ein System, das durch Multithreading den hohen Durchsatz einer GPU simuliert. Das bedeutet, der Overhead für die Aufgabenverteilung ist extrem gering.
Jobs können nur die Rechenlast eines einzelnen Frames tragen und sind, ähnlich wie CUDA/Shader-Funktionen, kleine Kernel. Schwere Berechnungen können die FPS dennoch beeinträchtigen, da Jobs manchmal dem Hauptthread zugewiesen werden. Wenn du lange Berechnungen ausführen möchtest, musst du sie entweder in viele kleine Jobs aufteilen, sonst sind .Net-Threads immer noch die beste Wahl.
Dann stellt sich die Frage: Wenn es ähnlich wie eine GPU ist, warum nicht einfach ComputeShader verwenden? Richtig, ComputeShader kann alles, was Jobs tun, und ist sogar bequemer. Außer:
- Wenn Daten häufig mit der CPU ausgetauscht werden müssen, ist die GPU dafür nicht gut geeignet. CPU-basierte Jobs haben hier einen Vorteil.
- Das ECS (DOTS)-System basiert auf Jobs, aus demselben Grund.
Beachte: WebGL unterstützt weder Jobs noch ComputeShader, auch keine Burst-Beschleunigung. Aber:
- WebGL wird durch WebGPU ersetzt. WebGPU unterstützt ComputeShader und wird von neueren Browsern bereits unterstützt (IOS17 muss in den Einstellungen aktiviert werden, 19 Preview ist standardmäßig aktiviert).
- In den Einstellungen kann WebAssembly 2023 die Multithreading-Unterstützung für Jobs aktivieren, und die Browserunterstützung ist umfassender. Aber offiziell heißt es, es sei nicht einmal ein experimentelles Feature und sollte nicht verwendet werden. Unity6 LTS stürzt ab, wenn es aktiviert ist. Wasm-Multithreading beschäftigt sie seit Jahren, und da DOTS derzeit mehr Beachtung findet, zusammen mit der .Net8-Unterstützung für Wasm-Multithreading, warten sie vielleicht auf Unity7, das .Net8 unterstützt.
Leistung
Leistungsindikatoren helfen, das Design und die Anwendbarkeit zu verstehen. Du kannst den Artikel auch erst lesen und später auf die Leistungstests zurückkommen.
Es wurden 8 Projekte getestet, zunächst die Leistung von 3 Allokatoren:
- BenchAllocatorTemp: Führt 100.000 Allokationen mit Allocator.Temp aus.
- BenchAllocatorTempJob: Wie oben, aber mit Allocator.TempJob.
- BenchAllocatorPersistent: Wie oben, aber mit Allocator.Persistent.
Das Ergebnis: TempJob ist am schnellsten, gefolgt von Persistent.
Dann wurden 4 Job-Modi getestet:
- BenchBaseLine: Führt 100.000 einfache Berechnungen mit einer For-Schleife als Referenzbasis aus.
- BenchIJob: Zeit für das Scheduling von 100.000 Jobs.
- BenchIJobParallelFor: Zeit für das Batch-Scheduling von 100.000 Jobs im Parallelmodus.
- BenchIJobParallelForBurst: Wie oben, aber mit aktiviertem Burst.
- BenchIJobParallelForBurstLoopVectorization: Plant 10 Jobs, jeder Job berechnet 10.000 Mal mit einer For-Schleife, mit aktivierter Burst-Vektorisierung.
Hier sind die Ergebnisse auf meinem PC:
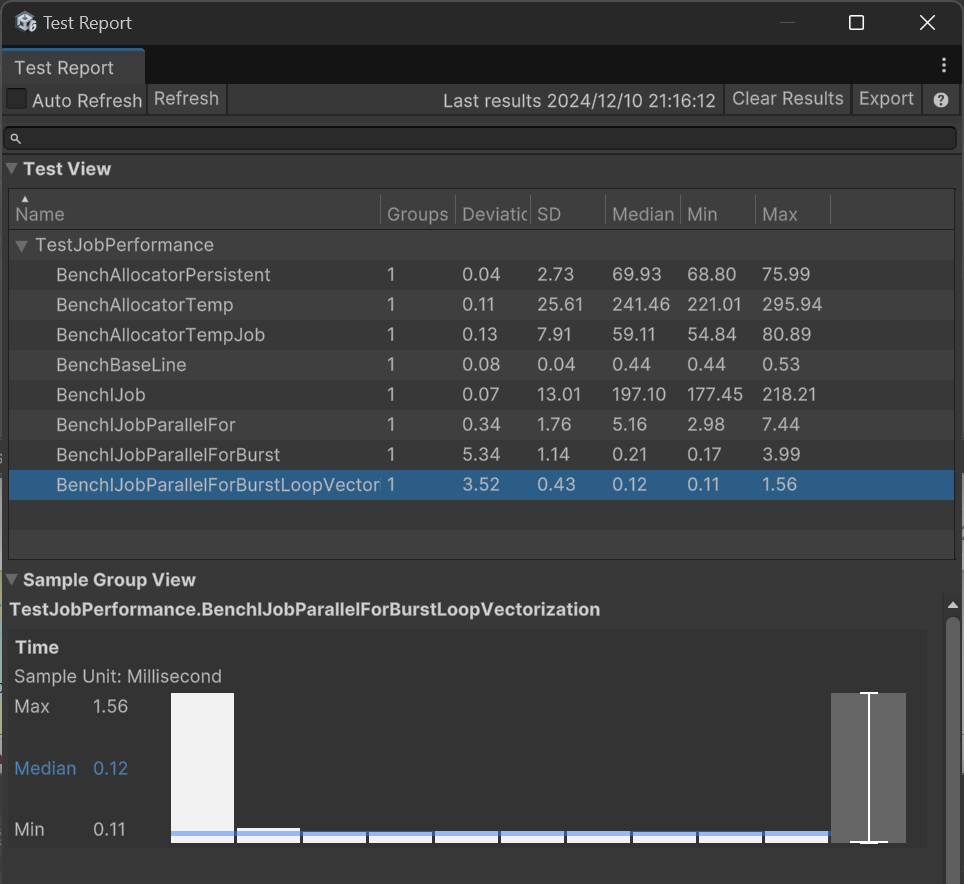
Median ist der Median der Testdauer in Millisekunden.
Man sieht, dass der Job-Scheduling-Overhead gering ist und für die Ausführung vieler Aufgaben ausgelegt ist. Natürlich wurden hier nur einfache Multiplikationen durchgeführt, daher ist die Job-Verbesserung begrenzt.
Datentypen
Zunächst unterstützt Burst keine C#-verwalteten Typen. Es können nur Typen verwendet werden, die die gleiche Länge wie in C haben und direkt memcpy-kopiert werden können (keine Serialisierung/Marshalling erforderlich). Diese heißen blittable und umfassen grundlegende Typen wie int usw. (char, string und bool sind manchmal verwaltet, nicht verwenden) sowie eindimensionale C-Style-Arrays (new int[5]) von blittable Typen. Da Jobs zwangsläufig mit Burst kombiniert werden, gilt diese Einschränkung.
Unity hat dafür den threadsicheren Typ NativeArray gekapselt, speziell für Jobs. Diese Typen können Daten mit dem Hauptthread teilen, ohne kopiert zu werden, da beim Kopieren nur der Datenzeiger übergeben wird und mehrere Kopien auf denselben Speicherbereich verweisen. Abgeleitete Typen sind NativeList, NativeQueue, NativeHashMap, NativeHashSet, NativeText usw.
Achtung: Code wie nativeArray[0].x = 1.0f oder nativeArray[0]++; funktioniert nicht, der Wert ändert sich nicht, weil kein Verweis zurückgegeben wird.
Threadsicherheit
Threadsicherheit wird durch Scheduling-Beschränkungen erreicht. Dieselbe NativeArray-Instanz kann nur von einem Job beschrieben werden, sonst wird eine Exception geworfen. Wenn Daten durch Segmentierung parallelisiert werden können, kann IJobParallelFor verwendet werden, um NativeArray in Batches zu verarbeiten. Bei schreibgeschützten Daten können Member-Variablen z.B. mit [ReadOnly] public NativeArray<int> input; gekennzeichnet werden.
Während ein Job schreibt, darf der Hauptthread nicht aus der NativeArray lesen, sonst gibt es einen Fehler. Man muss auf die Fertigstellung warten.
Speicherzuweisung (Allocate)
Zuerst: Native Typen müssen nach Gebrauch manuell mit Dispose() freigegeben werden. Sie werden nicht automatisch zerstört. Unity hat dafür eine Speicherleckverfolgung hinzugefügt.
Beim Erstellen (new) von Native-Typen muss zwischen drei Allokatoren gewählt werden: Temp, TempJob, Persistent. Die Allokationsgeschwindigkeit nimmt von schnell zu langsam ab. Temp hat eine Lebensdauer von 1 Frame, TempJob von 4 Frames. Was bedeutet das?
Tempbedeutet, dass es innerhalb der aktuellen Funktion verwendet werden soll und vor FunktionsendeDispose()aufgerufen werden muss. Vergisst man Dispose, meldet Unity beim nächsten Rendering sofort einen Fehler. Diese Allokation ist jedoch tatsächlich langsam.TempJobhat lockerere Fehlerbedingungen. Eigentlich soll es auch innerhalb von 1 Frame verwendet werden, aber Dispose kann im nächsten Frame erfolgen.Persistentmeldet keine Fehler, man muss selbst vorsichtig sein.
Der vorherige Leistungstest BenchAllocator hat die Leistung dieser drei getestet. Man sieht, dass Allocator.Temp viermal länger dauert als TempJob. Die Dokumentation sagt, Temp sei am schnellsten. Das ist entweder ein Bug oder ein Editor-Modus-Problem.
Einzelthread-Job ausführen
Der gesamte Ablauf besteht darin, eine eigene IJob-Klasse zu schreiben, sie im Hauptthread zu Schedulen und dann Complete aufzurufen, um auf die Fertigstellung des Jobs zu warten.
public struct MyJob : IJob {
public NativeArray<float> result;
public void Execute() {
for (int j = 0; j < result.Length; j++)
result[j] = result[j] * result[j];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}Das Problem ist jedoch: Wir verwenden Jobs für viele Aufgaben. Eine einzelne Aufgabe ist nicht sehr nützlich. Der parallele Modus der GPU ist nützlicher.
Paralleler Modus (Parallel Job)
Der obige Code wird zum parallelen Modus, indem IJob in IJobParallelFor geändert wird.
public struct MyJob : IJobParallelFor {
public NativeArray<float> result;
public void Execute(int i) {
result[i] = result[i] * result[i];
}
}
void Update() {
result = new NativeArray<float>(100000, Allocator.TempJob);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule(result.Length, result.Length / 10);
}
private void LateUpdate() {
handle.Complete();
result.Dispose();
}Der parallele Modus benötigt keine eigene For-Schleife. Execute wird für jedes Element einmal ausgeführt, ähnlich wie ein Shader.
Schedule(result.Length, result.Length / 10) bedeutet, dass Execute für jede Einheit von Index 0 bis result.Length ausgeführt und auf 10 Worker verteilt wird.
Die Leistungsunterschiede zwischen IJob und IJobParallelFor sind im vorherigen Leistungstest zu sehen.
Parallele Einschränkungen
In IJobParallelFor kann nur das Element i beschrieben werden, und es weiß nicht, in welches Member-Array geschrieben werden soll. Daher können alle Arrays nur das Element i beschreiben. Aber man kann [NativeDisableParallelForRestriction] zu NativeArray hinzufügen, um die Sicherheitsprüfung zu deaktivieren, und selbst sicherstellen, dass es keine Schreibkonflikte gibt.
Im schreibgeschützten Modus gibt es für alle Native-Container keine Einschränkungen.
Außerdem kann IJobParallelFor keine Schleifenvektorisierung aktivieren, es sei denn, die Berechnung verwendet bereits Vektorisierung (Aufruf anderer vektorisierter Funktionen). Andernfalls ist die Leistung nicht optimal.
Verwendung von NativeList und anderen Containern im parallelen Modus
Container außer Arrays wie NativeList können im parallelen Modus nur schreibgeschützt sein. Wie schreibt man dann?
Entwurfsmäßig ist NativeList in zwei Arbeitszustände unterteilt: Add und Set. Das korrekte Verwendungsmuster ist, dass ein Job Add-Operationen durchführt und ein zweiter Job Set-Operationen.
Für Add kann ParallelWriter und AsParallelWriter verwendet werden. Verwendung:
public struct AddListJob : IJobParallelFor {
public NativeList<float>.ParallelWriter result;
public void Execute(int i) {
result.AddNoResize(i);
}
}
public void RunIJobParallelForList() {
var results = new NativeList<float>(10, Allocator.TempJob);
var jobData = new AddListJob() {
result = results.AsParallelWriter(),
};
var handle = jobData.Schedule(10, 1);
handle.Complete();
Debug.Log(String.Join(",", results.ToArray(Allocator.TempJob)));
results.Dispose();
}In diesem Zustand hat NativeList eine feste Kapazität. Vor dem Start muss Speicher vorab allokiert werden, und es kann nur AddNoResize() verwendet werden. Diese Methode verwendet eine atomare Sperre für die Length-Eigenschaft, was die Leistung erheblich beeinträchtigt.
Dann verwendet man die verlustfreie Konvertierung von NativeList zu NativeArray: NativeList.AsDeferredJobArray(). Das zurückgegebene NativeArray ist faul (lazy) und wird erst bei der tatsächlichen Job-Ausführung konvertiert. Daher kann es vor der Ausführung beider Jobs übergeben werden:
var addJob = new AddListJob { result = results.AsParallelWriter() };
var jobHandle = addJob.Schedule(10, 1);
var setJob = new SetListJob { array = results.AsDeferredJobArray() };
setJob.Schedule(10, 1, jobHandle).Complete();Beachte: AsDeferredJobArray oder AsArray geben eine View zurück, also eine Ansicht der Originaldaten. Was Dispose benötigt, sind immer noch die Quelldaten.
Paralleler Modus für zweidimensionale Arrays
IJobParallelFor kann nur einzelne Elemente eines Arrays parallelisieren. Tatsächlich ist die Parallelisierung jeder Zeile eines zweidimensionalen Arrays nützlicher und kann zudem Schleifenvektorisierung aktivieren, was die Leistung erhöht. Dazu kann IJobParallelForBatch verwendet werden.
Zuerst erstellen wir ein flaches zweidimensionales Array [10*15] und planen es mit IJobParallelForBatch.Schedule(int length, int batchCount). batchCount gibt an, wie viele Daten jeder Job verarbeitet. Execute wird length/batchCount Mal ausgeführt.
var results = new NativeArray<float>(10*15, Allocator.TempJob);
var jobData = new MyJob2D {
result = results
};
var handle = jobData.Schedule(10*15, 15);
handle.Complete();
Debug.Log(String.Join(",", results));
results.Dispose();Dann folgt die Implementierung von MyJob2D.
[BurstCompile]
public struct MyJob2D : IJobParallelForBatch {
public NativeArray<float> result;
public void Execute(int i, int count) {
for (int j = i; j < i + count; j++) {
result[j] = i;
}
}
}Ausführungsergebnis:
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,
4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,
5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,
9,9,9,9,9,9,9,9,9,9,9,9,9,9,9
UnityEngine.Debug:Log (object)Diese Methode kann durch Burst automatisch die Schleifenvektorisierung aktivieren. Daher betrug die Zeit für 100.000 Berechnungen im Leistungstest 0.09 ms und war am schnellsten.
Weitere Einschränkungen
- Du kannst in einem Job keinen weiteren Job starten.
Kombination mit Async
Die obigen Beispiele planen Jobs in Update und schließen sie in Late ab, um den Update-Code zu beschleunigen. Für einmalige Aufgaben muss es nicht so umständlich sein. Man kann Async verwenden, um direkt zu warten, ohne das Rendering zu blockieren. Dazu kann die Erweiterungsmethode CompleteAsync aus dem Paket verwendet werden:
async void GenerateMesh() {
result = new NativeArray<float>(100000, Allocator.Persistent);
MyJob jobData = new MyJob{
result = result
};
handle = jobData.Schedule();
await handle.CompleteAsync();
}Beachte: Dieser Modus erfordert den Persistent-Allokator, da die Ausführung nicht unbedingt innerhalb eines Frames abgeschlossen wird.
Burst
Burst basiert auf LLVM und ist eine als “High-Performance C#” bezeichnete Teilmenge von C#, im Grunde C-Code. Es ist normalerweise 10 bis 100 Mal schneller als Mono, was auch zeigt, wie langsam Mono ist.
Burst kann die Ausführungsgeschwindigkeit von Jobs weiter steigern. Für das obige Beispiel reicht diese eine Zeile:
[BurstCompile]
public struct MyJob : IJobParallelFor {
...
}Im Leistungstest für IJobParallelFor verbesserte sich die Ausführungszeit allein durch diese Zeile von 5.16 ms auf 0.21 ms. Damit übertrifft die Job-Geschwindigkeit endlich die einer For-Schleife.
Hinweis: Die obigen Leistungstests basieren auf 10 Workern. Feineinstellungen der Worker-Anzahl können zu anderen Ergebnissen führen.
Vektorisierung
Vektorisierung packt mehrere Berechnungen in eine Anweisung, z.B. sind float3-Berechnungen von Natur aus vektorisiert. Für Vektorisierung sollten am besten Typen und Methoden der Unity.Mathematics-Bibliothek verwendet werden, sonst kann es fehlschlagen.
Wenn keine vektorisierten Berechnungen durchgeführt werden, kann die Schleifenvektorisierung helfen. Der vorherige Leistungstest verbesserte sich dadurch auf 0.09 ms, siehe Kapitel über zweidimensionale Arrays. Schleifenvektorisierung bedeutet, dass einige parallelisierbare For-Schleifenberechnungen in einem Befehlssatz ausgeführt werden. Burst erkennt und optimiert dies automatisch.
Wie weiß man, ob ein Job korrekt vektorisiert wurde?
Öffne das Burst Inspector-Tool (im Jobs-Menü).
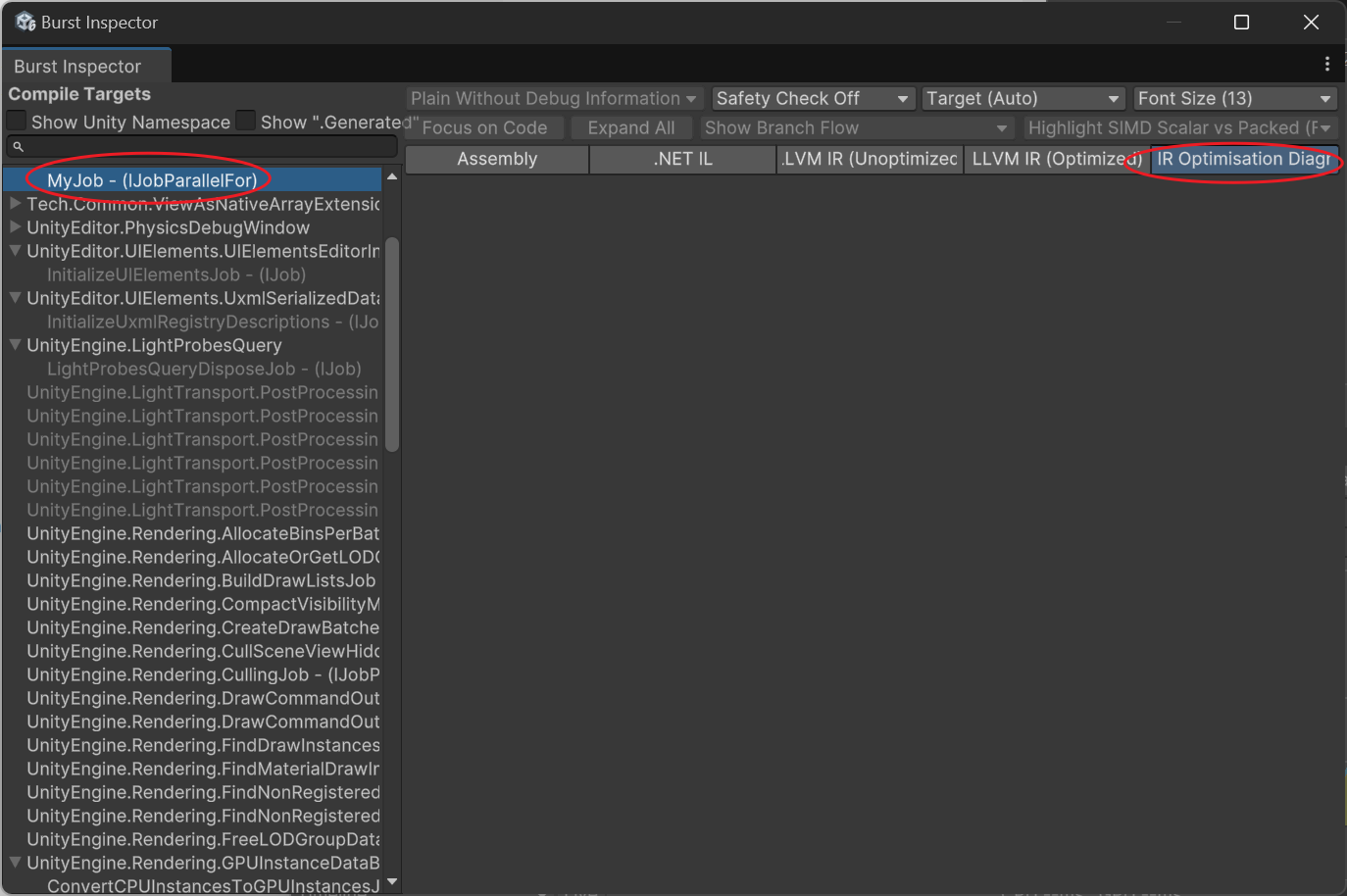
Wähle deine Funktion aus und prüfe im Assembly, ob avx-Befehle vorhanden sind, und ob IR Optimisation Warnungen anzeigt. Wenn keine Vektorisierung erfolgt, wird angezeigt:
---------------------------
Remark Type: Analysis
Message: test.cs:30:0: loop not vectorized: call instruction cannot be vectorized
Pass: loop-vectorize
Remark: CantVectorizeInstructionReturnTypeHäufige Meldungen:
- loop not vectorized: call instruction cannot be vectorized bedeutet, dass eine nicht vektorisierbare externe Funktion aufgerufen wurde.
- loop not vectorized: instruction return type cannot be vectorized bedeutet normalerweise, dass eine bereits optimierte Funktion aufgerufen wurde, daher kann keine zweite Vektorisierung erfolgen. Das ist normal.
Konvertierung zwischen Job- und Unity-Daten
Der schmerzhafteste Aspekt bei der Verwendung von Jobs und Burst ist die Konvertierung verschiedener Daten in NativeArray.
Zum Beispiel muss Vector3 in float3 geändert werden. Bei gleicher Größe ist eine direkte Umwandlung möglich. Beispiel:
var floats = new NativeArray<float3>(100, Allocator.TempJob);
NativeArray<Vector3> vertices = floats.Reinterpret<Vector3>();
Vector3[] verticesArray = vertices.ToArray();
floats.Dispose();Man kann auch in Strukturen reinterpretieren, z.B. 3 float1 in 1 vector3:
var floats = new NativeArray<float>(new float[] {1,2,3}, Allocator.TempJob);
NativeArray<Vector3> aaa = floats.Reinterpret<Vector3>(sizeof(float));
Debug.Log(string.Join("\n", aaa.Select(v => v.ToString())));
floats.Dispose();(1.00, 2.00, 3.00)Für Casts wie NativeArray<int> zu NativeArray<ushort> muss man eigene Job-Konvertierungen erstellen.
JobSystem mit automatischer Batch-Ausführung auf der WebGL-Plattform
JobSystem-Code wird auf der WebGL-Plattform vom Hauptthread ausgeführt, daher würde IJobParallelFor mit vielen Aufgaben das Spiel direkt einfrieren.
Man kann eine eigene AdaptSchedule-Schnittstelle erstellen, die automatisch erkennt, ob es sich um eine WebGL-Umgebung oder eine Multithreading-Umgebung handelt. Unter WebGL wird in Schritten entsprechend der worker-Anzahl Frame für Frame ausgeführt. Jeder Schritt yielded ein Awaitable zurück, damit der Hauptthread Luft bekommt.
Schlusswort
Burst ist eigentlich ein Kompromiss, um Code zu beschleunigen. Das führt zu einer Mentalität, bei der alles Burst-kompatibel sein soll, was schließlich zu hässlichem Code und langsamer Kompilierung führt. Die DOTS-Bibliothek ist voll von solchen Spuren. Unity wird mit zunehmender Entropie ohnehin immer aufgeblähter und die Kompilierung immer langsamer. Für eine breitere Anwendung von DOTS muss dieses Problem gelöst werden.
Unity7 wird .Net8+ und CoreCLR unterstützen, was die Editor-Kompiliergeschwindigkeit erhöht und viele neue .Net-Funktionen nutzbar macht, was die Kommunikation mit C-Code reduziert. Lasst uns ein wenig hoffen, dass wir in Zukunft Burst nicht mehr so häufig benötigen.
Bearbeitung im Februar: Der für CoreCLR verantwortliche Direktor ist aufgrund von Meinungsverschiedenheiten zurückgetreten. Macht euch nichts draus.

47c675c
