Formeln und Implementierung von Grund auf für einfache und multiple lineare Regression
Die Formeln selbst sind sehr kurz und dienen als erste Lektion in ESL, sehr grundlegend.
Es gibt viele Bibliotheken, die das können, aber da ich kürzlich in meiner Entwicklung GPU-Berechnungen für Regressionen benötigte (was die Geschwindigkeit um ein Vielfaches erhöhen kann), schreibe ich nebenbei einen Blogbeitrag, um zu testen, ob die Formeldarstellung auf der Website korrekt funktioniert.
Was ist lineare Regression?
Einfach gesagt, wird ein linearer Trend in den Daten durch eine lineare Gleichung dargestellt.
Einfach (univariat): $y=mx+b$ Mehrfach (multivariat): $y=m_1x_1+m_2x_2+…+b$
 Man kann sich vorstellen, dass jeder Punkt ein Stern gleicher Masse ist, und die Regressionslinie ist ein langer Stab, der in diesem Gravitationsfeld seine endgültige Gleichgewichtsposition einnimmt.
Man kann sich vorstellen, dass jeder Punkt ein Stern gleicher Masse ist, und die Regressionslinie ist ein langer Stab, der in diesem Gravitationsfeld seine endgültige Gleichgewichtsposition einnimmt.
Formel für einfache univariate lineare Regression (Linear regression)
Simple OLS regression wird separat aufgeführt, weil sie anschaulicher und leichter zu verstehen ist:
Es ist einfach die Kovarianz geteilt durch die Varianz von x. Wie man zu dieser Formel gelangt, wird hier ausgelassen, aber man sollte bereits die Eleganz dieser Formel spüren.
Dann ist b einfach, nachdem m ermittelt wurde, durch Einsetzen zu finden:
Implementierung in pyTorch Code
PyTorch wird für die GPU-Beschleunigung verwendet. Nehmen wir an, wir haben einen y-Datensatz mit den NVDA-Preisen vom Februar 2018:
import torch
y = torch.tensor([
225.58, 228.8 , 217.52, 230.93, 228.03, 232.63, 241.42, 246.5 ,
243.84, 249.08, 241.51, 242.15, 245.93, 246.58, 246.06, 242. ,
232.21, 236.54, 235.65, 242.16
])Dann generieren wir x:
x = torch.arange(len(y)).float()tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15., 16., 17., 18., 19.])
Regressionscode (hier nur der Lesbarkeit halber, mit wiederholten Berechnungen):
demean_x = x - x.mean()
demean_y = y - y.mean()
n_1 = x.shape[0] - 1
m = torch.sum(demean_x * demean_y / n_1) / torch.sum(demean_x ** 2 / n_1)
b = y.mean() - m * x.mean()
print(m, b)(tensor(0.7734), tensor(230.4090))
Lassen Sie uns die Ergebnisse plotten:
from matplotlib import pyplot as plt
plt.plot(x, y)
plt.plot(x, m * x + b)
plt.show()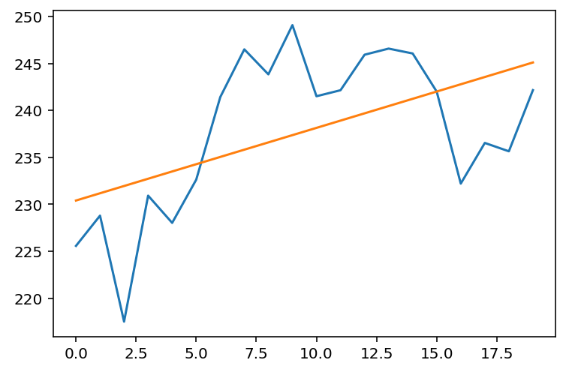 Sieht gut aus🥂.
Sieht gut aus🥂.
Formel für multiple lineare Regression (Multiple Linear regression)
Im Wesentlichen dasselbe wie einfache Regression, hier in Matrixschreibweise, und sogar kürzer:
Eine Formel löst alles, gilt auch für einfache lineare Regression.
Nebenbei, $X^TX$ taucht überall auf, es gibt sogar einen Private-Equity-Fonds namens XTX.
Implementierung in pyTorch Code
Die Formel enthält viele implizite Informationen, und eine textuelle Beschreibung wäre zu umständlich. Lassen Sie uns dies mit Code implementieren.
Ich denke immer, wenn Formeln in Lehrbüchern und Artikeln entsprechenden Code und Ergebnisse für jeden Schritt hätten, gäbe es viel weniger Fragen beim Lesen, denn Code muss vollständige Informationen enthalten, um ausführbar zu sein.
Hier wird eine bivariate lineare Regression zur Demonstration verwendet. Am häufigsten ist eine quadratische Gleichung ($y=ax^2+bx+c$), also eine Kurvenanpassung. Warum ist es eine bivariate Regression, wenn es eine univariate Gleichung ist? Weil die bivariate Regression zwei unabhängige Variablen meint: $x, x^2$
Wir verwenden weiterhin die obigen x, y Daten. Lassen Sie uns zunächst die X-Matrix generieren, die $x, x^2$ enthält. Beachten Sie jedoch, dass hier die erste Spalte eine Konstante 1 enthält, um die Matrix positiv definit zu machen und b (in der Abbildung ${\hat\beta}_0$) zu berechnen:

X = torch.stack([torch.ones(x.shape), x, x ** 2]).Ttensor([[ 1., 0., 0.], [ 1., 1., 1.], [ 1., 2., 4.], [ 1., 3., 9.], [ 1., 4., 16.], [ 1., 5., 25.], … [ 1., 15., 225.], [ 1., 16., 256.], [ 1., 17., 289.], [ 1., 18., 324.], [ 1., 19., 361.]])
Dann kann direkt gerechnet werden:
b, m1, m2 = (X.T @ X).inverse() @ X.T @ y
print(b, m1, m2)(tensor(220.5210), tensor(4.0694), tensor(-0.1735))
Ja, das ist das Ergebnis. Lassen Sie uns plotten:
plt.plot(x, y)
plt.plot(x, m1 * x + m2 * x**2 + b)
plt.show()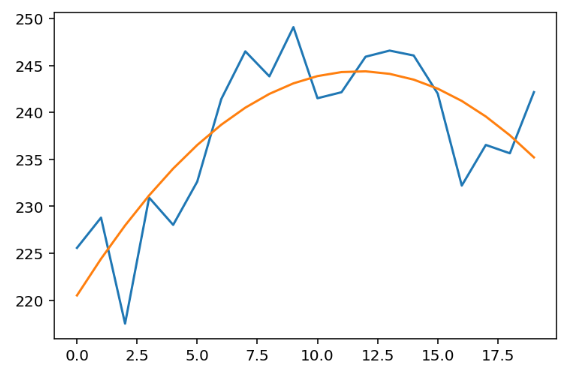
Sehr perfekt👏, ist es nicht einfach? Aber eigentlich gibt es dahinter noch wichtigere Konzepte, wie z.B. den Fall mehrerer Lösungen und orthogonale Behandlung.
Kollinearität und Orthogonalitätsprobleme
In der Praxis sind Probleme, die durch einfache polynomiale Regression gelöst werden können, nicht häufig. Normalerweise geht es um die Regression von Beobachtungswerten, und Beobachtungswerte sind grundsätzlich nicht vollständig unabhängig, d.h. die Kovarianz zwischen den x-Werten ist nicht 0. Die Unabhängigkeit der x-Werte voneinander gewährleistet, dass der Koeffizient nur für dieses x verantwortlich ist und nicht von anderen x-Werten beeinflusst wird. Dies erfordert eine orthogonale Anpassung.
Im Detail wird hier nicht darauf eingegangen. Wenn Sie das Problem schnell lösen möchten, hier eine grobe Lösung: Verwenden Sie die QR-Zerlegung. Berechnen Sie mit Q, R = torch.qr(X) und verwenden Sie dann die Formel $b, m_1,…,m_n=R^{-1}Q^Ty$, um es zu lösen.
Wenn Sie interessiert sind, können Sie ESL 3.2.3 Multiple Regression from Simple Univariate Regression lesen, wo multiple Regression aus einfacher univariater Regression abgeleitet wird.
Autor: Zhang Jianhao Heerozh (heerozh.com)

1700515